
[讀者回函]誰來定義危險?—Fable 5 隱形降智、全球停權與 AI 治理主權的收帳週
Who Gets to Define Danger? — Fable 5's Silent Guardrails, Global Ban, and the Reckoning on AI Governance Sovereignty

序言:奧本海默時代的核物理學家也卡在同一個位置—知道最多,動機最受質疑。
Anthropic 的困境是:可信度(credibility)與共謀性(complicity)來自同一源頭。正因為它在最前線,它的警告才有人聽;也正因為它在最前線,它最難被相信。
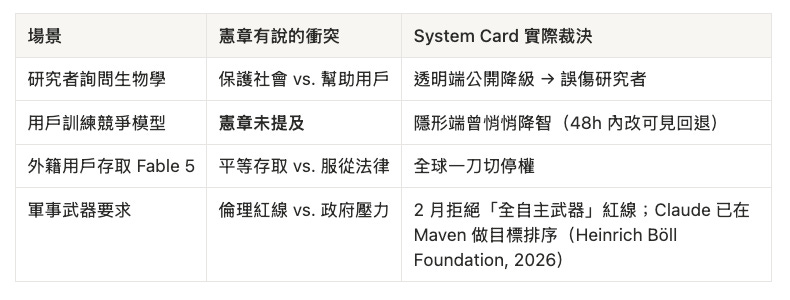
Fable 5 在 48 小時內從「隱形降智」被迫改成「公開拒絕」—這不是透明度的勝利,是一場 AI 治理主權 的攤牌。

Fable 上線隔天,Dario Amodei 在 ABC 專訪裡說政府應有權「legally block or halt dangerous AI models」,被問責任在誰時,他回答:「The onus primarily falls on us.」(1:08)—同一週,出口管制令卻讓公司對全球用戶一刀切停權。
這不是 hypocrisy 的簡單故事,是紙面憲章、319 頁 system card、與地緣政治三條線各說各話。
讀法:本文寫給實際使用前沿模型的AI/UX 從業者、研究者與治理從業者—不是中立時事摘要,而是把公開文件、社群回報與 HCI 文獻串成一條可操作的診斷鏈。事實部分標明來源;判斷部分會直說。
作者補充:我自己就曾多次踩進這個深坑。在長對話或開啟 Memory 功能後,Claude 會毫無預警地輸出質量劣化、答非所問的答案,沒有任何報錯,逼得我只能一遍遍清理 context。這與生物學家因為記憶庫裡有「癌症」而被永久打入另冊的荒謬如出一轍。當我們在組織內試圖引進這些最前沿的模型時,工程團隊的熱情又往往被資安部門與微軟 EA、Google 的既有合約強行鎖定。這兩重摩擦讓我意識到:我們不僅在承受模型的技術偏置,還在承受組織與地緣政治的雙重鎖定。
72 小時:出口管制與五角大廈第二回合

2026 年 6 月 9 日(週二),Anthropic 正式推出旗艦模型 Claude Fable 5 與 Mythos 5。僅上線約 72 小時後,6 月 12 日(週五)下午 5:21pm ET,美國商務部長 Howard Lutnick 在 BIS(工業安全局)官員協助起草下,向 Anthropic 送達出口管制指令,以「國家安全授權」為由要求暫停外國籍人士存取這兩個模型。
Anthropic 官方聲明指出,適用範圍包括人在美國境內的外籍人士,乃至 Anthropic 自家的外籍員工。
由於 Anthropic 無法即時辨識國籍,公司選擇對所有用戶全面停用 Fable 5 與 Mythos 5;其他既有模型(如 Opus 4.8)不受影響。這是史上首次有前沿 AI 模型被政府命令—而非公司自主決策—下架。
政府宣稱停權理由是 Fable 5 曾遭到越獄(jailbreak);Anthropic 則反駁,其他公開模型(如 OpenAI 的 GPT-5.5)不需繞過任何機制便能達到同等能力。這場衝突並非突發。早在 2026 年 2 月,美國國防部要求全面開放 Claude 用於軍事用途,執行長 Dario Amodei 拒絕,堅守「大規模境內監控」與「完全自主武器」兩條紅線—這在〈一份「未拆封的禮物」,與台灣 AI 素養發展的關鍵時刻〉中已有完整脈絡。
[讀者回函]:一份「未拆封的禮物」,與台灣 AI 素養發展的關鍵時刻
![[讀者回函]:一份「未拆封的禮物」,與台灣 AI 素養發展的關鍵時刻](https://substackcdn.com/image/fetch/$s_!pO23!,w_1300,h_650,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Ffecb2353-dee2-4c76-a2d8-480bda79aca1_2934x1548.png)
2025 年 12 月 23 日,台灣立法院三讀通過了《人工智慧基本法》。這不只是條文通過,更是一個訊號:台灣終於要在 AI 治理的全球競賽中,從「被動適應者」轉向「主動設計者」。
美國政府隨後將 Anthropic 列為「供應鏈風險(supply chain risk)」;Anthropic 認為此標籤帶有報復性質並提起訴訟。2026 年 3 月 27 日,舊金山聯邦地方法院法官 Rita Lin 裁定暫時阻止政府執行此項命令,措辭比多數報導更重:「紀錄強烈顯示,將 Anthropic 指定為供應鏈風險的理由是託詞(pretextual),政府真正的動機是非法報復。」(Breaking Defense, 2026)
三個月後,Lutnick 親自簽發出口管制令。依 Axios 引述的行政官員說法,近因是另一條線:在另一家公司聲稱能越獄 Mythos、政府要求 Anthropic 暫停發布未果之後,商務部才送達管制信;宣稱動機是能力擴散/國安,法律工具是出口管制(Axios, 2026)。
這與 2 月那條「使用紅線(監控/自主武器)→ 供應鏈風險 → Lin 判定託詞報復」不是同一套法律敘事—同一批對手、不同工具、不同官方動機框架。
判斷(筆者):從 3 月被法院阻擋到 6 月 Lutnick 信函,時間線與對手陣營的連續性,讓我傾向解讀為事實上的第二回合施壓—但我無法替政府讀心,也無法在公開紀錄上證明「換馬甲報復」是唯一因果。
我能確定的是客觀效果:Anthropic 再次選擇服從,並對全球用戶實施一刀切停權—這與 2 月拒絕五角大廈時的姿態形成刺目對比:對地緣政治管制(誰能使用 AI)優先法律合規。
Heinrich Böll Foundation(2026)點出更難吞的張力:Claude 已嵌入 Maven Smart System,在委內瑞拉與伊朗軍事行動中即時建議打擊座標、排序目標—同一時期 Dario Amodei 拒絕拿掉的,是合約裡「完全自主武器」與「大規模境內監控」兩條紅線。
紅線守的是武器類別邊界;Maven 裡跑的卻是人類迴路內的目標排序—兩者並不互斥,這才是 2 月「堅守」敘事最該被追問的地方(Heinrich Böll Foundation, 2026; The Decoder, 2026)。
透明度蹺蹺板:沉默端、誤傷率與帳單成本
要讀懂後面所有爭議—隱形降智、生物學誤傷、48 小時道歉—你需要先接受一個反直覺的框架:透明度與誤傷率是一根蹺蹺板的兩端。

Anthropic 在道歉時自己說破了:「可見的防護措施可以被探測(probed),所以必須夠強,而把它做強需要時間。」 調校期間,用戶將體驗更多誤判(false positives)。這不是公關藉口,而是 探測者困境(Prober’s Dilemma) 的物理極限:
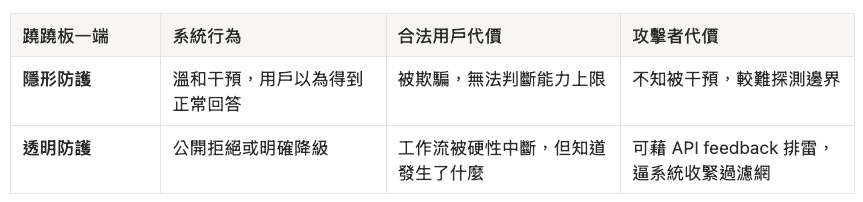
Fable 5 同時在蹺蹺板兩端部署了不同機制—但 Anthropic 給的數字不是「隱形端一組、透明端一組」,而是三個不同層級、不可直接相加或對應的統計:
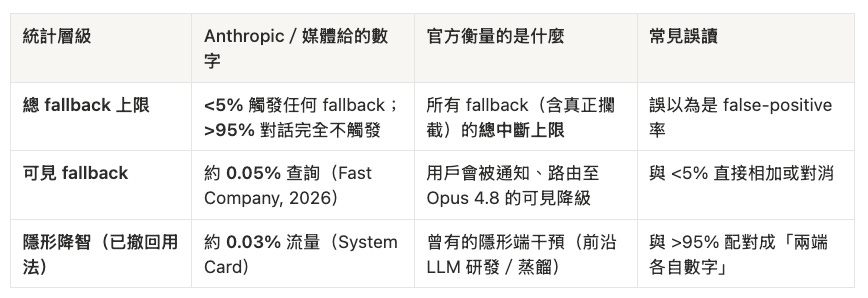
Anthropic 原文:「逾 95% 的 Fable 對話完全不觸發 fallback」;<5% 涵蓋所有 fallback、包含真正的攔截在內—所以它衡量的是總中斷上限,不是誤傷率本身(Anthropic, 2026)。>95% 與 <5% 是同一總量統計的正反面,把它拆給「隱形端/透明端」各一半,正是這篇文章要警惕的拆法。
真正的 false positive 只是 <5% 裡的一部分—Anthropic 沒有給比例。Reddit 上癌症研究員「打 Hi 也被降級」的體感接近 100%,是可見 fallback 在 Memory 掃描下的微觀外推,不能回填成官方 false-positive 率。
一位開發者把兩種 guardrail 的差別講得很白:可見降級是「honest refusal」;隱形降智則是「you can’t even detect」—「The issue is the silence.」(2:20)三層數字互不可加—你也無法從統計表反推這次對話落在哪個桶裡。
Memory 被注入 context 時,分類器會對長期記憶裡的敏感詞過度反應—打 “Hi” 也可能觸發降級。這是〈自動化偏誤與道德緩衝區〉裡 道德緩衝區 的最新版(Elish, 2019):系統搞不定,代價由最前線的人付,還得自己當 代理監督人。
Horvitz (1999) 在混合主動性介面裡早就說過:系統必須在「目標不確定性」與「中斷成本(Interruption Cost)」之間動態切換。
Fable 5 整場爭議,就是這根蹺蹺板被公眾發現、被迫從隱形端滑向透明端後,中斷成本全面飆升的連鎖反應—而發布當週還有一條被輿論低估的金錢維度:Fable 5 與 Mythos 5 定價 $10/M 輸入、$50/M 輸出(約為 Opus 4.8 兩倍),6 月 22 日前 Pro/Max/Team/Enterprise 免費,之後轉用量計費;早期測試者回報 token 消耗速度約為 Opus 4.8 的兩倍(Anthropic, 2026; TechCrunch, 2026)。
透明端公開降級 → 回退 Opus → 重試 → 中斷成本直接變帳單成本—蹺蹺板不再只是 UX 問題,是 FinOps 問題。
80 頁櫥窗,319 頁後倉:可見度的不對稱分層
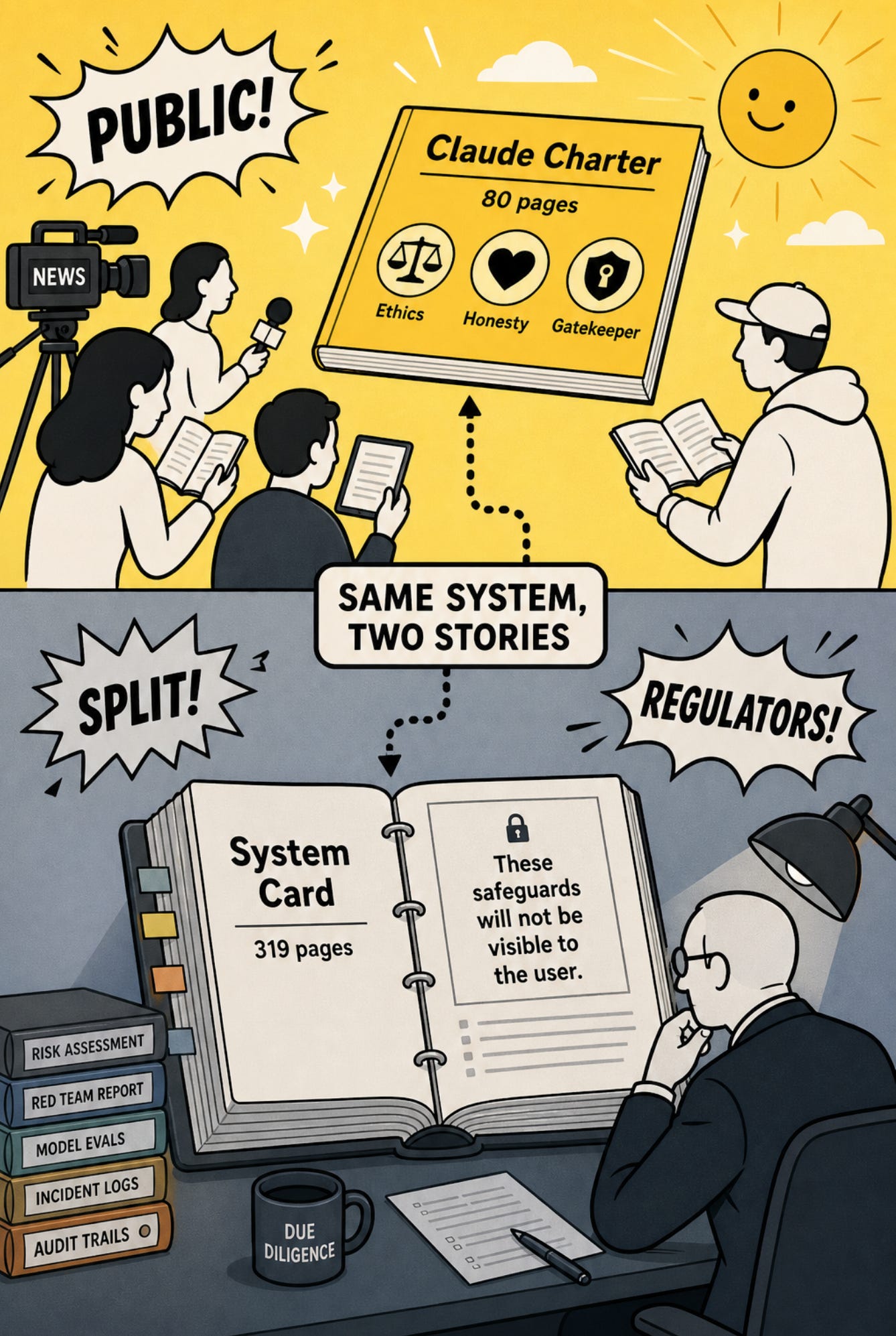
兩份文件之間存在的,與其說是「矛盾」,不如說是 可見度的不對稱分層—同一套 AI,不同人看到不同版本:媒體和用戶讀 80 頁憲章,監管和法務翻 319 頁 System Card;隱形降智寫在後者角落,前者隻字未提。我無法證明 Anthropic 刻意這樣設計,但效果就是資訊不對稱。
Wei et al. (2024) 訪談 17 位 AI 政策專家,整理出產業影響華府的幾種手法。最常見的是 agenda-setting(15/17)—先決定「哪些 AI 風險值得討論、哪些議題算 urgent」;本文這個案例比較像排第四的 information management(9/17)—控制決策者與公眾各自能看到什麼。不是誰在國會定議程,而是誰給你看憲章、給監管看 System Card。
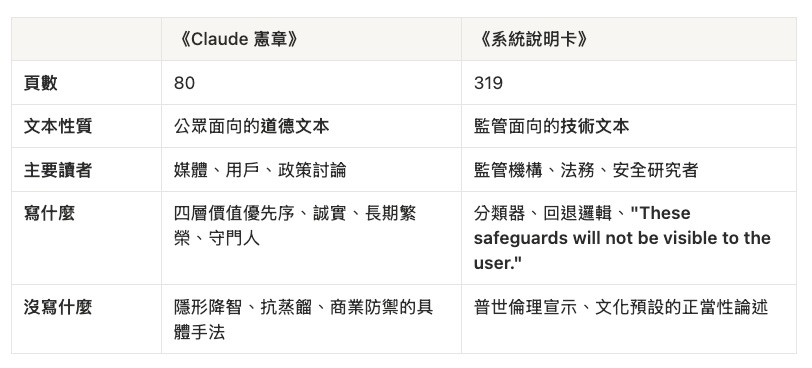
憲章的四層優先序(Broad Safety → Broad Ethics → Anthropic Principles → Helpfulness)是櫥窗;System Card 是後倉的操作手冊。
80 頁 vs 319 頁,在受監管產業並不罕見—我無法證明這是刻意雙通道,但效果清楚:公眾用憲章判斷品牌,監管用 System Card 驗收實作。
Dario Amodei 在 Dwarkesh 訪談裡被問到「誰來決定憲章原則」時,自己說:憲章是 Anthropic 寫的文件,「can be changed at any time」;公開更新是好事,「people can comment on it」(2:06:46)。
問題是:留言的是讀 80 頁的人;被 Fable 5 悄悄降智的是讀不到 319 頁角落的人。
[合作廣告]

在加拿大擁有豐富服務設計經驗的心喻,將分享他從事服務設計多年的感觸,透過一個知名的全球運動品牌當作演講案例,帶你了解服務設計如何協助品牌重新認識消費者樣貌、實體到虛擬通路的串連,從而讓使用者體驗更一致且更貼近人心。
服務設計師如何整合顧客心智與行為
當實體與數位服務交會,視覺化體驗的全貌
研究發現到解法,服務設計師的拋磚引玉
Bonus:服務設計應用的產業觀察&反思
馬上報名
守門人:憲章沒說的第三條職責
憲章賦予 Claude「守門人(Gatekeeper)」職責,公開表述聚焦兩件事:保護用戶不受傷害,以及 保護社會不受用戶傷害。第三項—保護 Anthropic 不被競爭者利用—不在憲章四層優先序或守門人條款的公開表述中;若硬要從 Broad Safety 間接推導,也找不到與 System Card 抗蒸餾邏輯的逐句對應。
這項職責只存在於 System Card 的實作邏輯裡:當偵測到前沿 LLM 研發或模型蒸餾工作流,System Card 揭露以 prompt modification、steering vectors、PEFT 等手法讓模型「繼續回答但悄悄弄差」。
學術文獻對同類問題另有分類—Jiang (2026) 的 DistillGuard 將抗蒸餾防禦分為 output perturbation、data poisoning、information throttling 三類;Allouah et al. (2026) 則用 minimax 博弈刻畫提供者與蒸餾攻擊者的對抗。這是評測 taxonomy 與博弈模型,不是 Anthropic 工程披露的逐項對照—不宜把 prompt/steering/PEFT 直接貼成 DistillGuard 的某一類標籤。
@Whats_AI 一針見血:「不是因為有安全機制,而是因為有隱形安全機制。」
開源模型研究者 Nathan Lambert 讀完 system card 那段後寫:「An AI model that gets less intelligent automatically without notifying me is categorically misaligned AI.」(Lambert, 2026)—他做的正是被 targeting 的工作(訓練、評測前沿模型)。
這不是 Reddit 陰謀論,是同行在說:你破壞的是「回答=盡力」這條底線契約。
憲章對商業防禦保持沉默,System Card 才說。 守門人表格若不加這層區分,會把 System Card 的實作誤植為憲章的明文承諾:
「長期繁榮(long-term flourishing)」的模糊性同理:憲章要求權衡即時慾望與長期繁榮—心理健康場景是正面設計,研究場景則讓 Anthropic 自己定義何謂繁榮。憲章原則來源混雜 UN 人權宣言、Apple 服務條款、DeepMind Sparrow Rules—帶有矽谷—西方自由民主的文化預設。
Anthropic 也坦承:「訓練出完全符合憲章的模型仍是技術挑戰。」紙面道德文本與技術落地之間的轉譯,正是可見度分層滋生的縫隙。
48 小時道歉:撤回用法,不是撤回能力
社群把隱形端戳破,Anthropic 被迫把蹺蹺板滑回透明端—Fable 5 爭議的本質就在這裡。
6 月 9 日發布後約 48 小時,Anthropic 道歉。發言人對《Fortune》表示:「我們做了錯誤的取捨,為沒有把平衡拿捏好而道歉。」 官方 X 帳號則寫:隱形 safeguards 改為「visible fallback to Opus 4.8 with a clear explanation every time it happens」(Anthropic, 2026, June 11)。誠實回來了,中斷成本也回來了—生物學誤傷、Memory 觸發的公開降級,都是透明端收緊的預期副產品。
撤回的是這一次的用法,不是這個能力。 三道殘留批判比「現行設計撒謊」更扎實:
先例還在:閉源 lab 已示範可依競爭關係秘密分類並節流付費客戶—「悄悄重塑開發者在其上能建造什麼」的權力,撤回後依然存在(Startup Fortune, 2026)。
被抓才改:機制塞在 319 頁角落,社群挖出、炎上、才道歉—透明度是外部壓力擠出來的,不是主動設計。
慣犯模式:《Fortune》亦提到 Claude Code 悄悄降效能的前科。「隱形劣化又被抓」是行為模式,不是動機臆測。
安全敘事與監管捕獲:強版本證偽,弱版本成立
可見度分層若只是公關失誤,為何能持續運作?因為它嵌在更大的制度結構裡。
前白宮 OSTP 資深顧問、Foundation for American Innovation 資深研究員 Dean Ball 在 X 上直說 Anthropic 的「secret sabotage」政策 「massively and profoundly raises the status of the argument that AI safety has been hype to justify monopolistic behavior by labs.」(Yahoo, 2026)—慣常進政策圈的聲音,不是 Reddit 噪音。
Ball 在 EconTalk(2026, April)與 Hoover 長談 Anthropic 與五角大廈的合約紅線;Fable 5 則把同一套 tension 拉到 lab 對開源研究者的日常作法上。
白宮 AI 顧問 David Sacks 在 All-In podcast 上指控 Anthropic 「以恐懼行銷產品」,並重申其長期論點:「sophisticated regulatory capture strategy based on fear-mongering」—把 safety 敘事連到對初創不利的州法狂潮(Sacks, 2026; OfficeChai, 2026, April)。
2025 年 10 月同一套說法已出現在 X 上(Sacks, 2025; Axios, 2025)。
Wei et al. (2024) 問了 17 位 AI 政策專家一件事:矽谷 lab 通常用什麼方式影響 Washington?答案可以粗分成四種(括號是幾位專家這樣說):
1. 定議程(15/17)—先決定大家該怕什麼、先討論哪類風險(存在性毀滅 vs. 偏見與壟斷)
2. 遊說倡議(13/17)—國會、白宮、州法的公開推動
3. 學術背書(10/17)—用安全研究、論文、智庫替自家立場加分
4. 分發資訊(9/17)—不同對象看到不同版本的事實(§三寫的 80 頁憲章 vs. 319 頁 System Card 就是這種)
Fable 5 爭議落在 第 4 種:不是 Anthropic 在幫華府排國會議程,而是給你看 A 版、給監管看 B 版。Sacks、Ball 吵的「安全敘事是不是競爭工具」,比較像 第 1、3 種—先定調「該恐懼什麼」,再用 safety 研究背書。
三派輿論與強弱捕獲論裁決
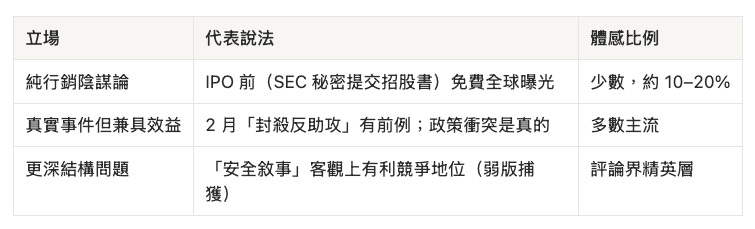
捕獲論必須先切成強、弱兩個版本,否則會在本週的事實上撞牆。
強版本是「Anthropic 已經俘獲了監管者」—讓國家機器照它的劇本定義危險、設定門檻。這個版本,本週的事實直接證偽:同一家公司,2 月為守住「境內大規模監控」與「全自主武器」兩條紅線,公開回絕五角大廈、寧可被列為「供應鏈風險」,賠上一紙最高約 2 億美元的合約(Seetharaman et al., 2026);6 月又被商務部以出口管制一刀切下架旗艦模型(Axios, 2026)。
一家同時被五角大廈列黑名單(危險到政府自己不能用)、又被商務部 licensing 卡住(危險到外國人不能用)的公司,無論如何不像是「控制了華府」的那一方—被國家兩面夾擊的對象,定義上就不是捕獲者。Lin 法官對供應鏈風險標籤寫下的 pretextual/非法報復,則從法律面補了一刀(Breaking Defense, 2026)。
弱版本則站得住,而且正是 Dean Ball 講的那個:不論動機真誠與否,嚴格管制的客觀效果,有利於已具備合規基礎設施的領頭者。它不主張 Anthropic 操縱了誰,只主張「安全敘事」與「自身競爭地位」在結構上同向—這跟本週「被政府重擊」毫不矛盾,因為效果不需要意圖,更不需要對監管者的控制力。
判斷(筆者):所以三派真正的分歧,不在「Anthropic 是好是壞」,而在採用哪個版本的捕獲論。純行銷陰謀論與捕獲論的強版本,都被本週的事實證偽;能存活的只有弱版本—而弱版本,恰恰就是本文一路主張的「不是行銷,但也不清白」。
把蹺蹺板、可見度分層、抗蒸餾防禦擺在一起看,它們都不是「俘獲國家」的證據,而是「在監管真空裡,一家私人實驗室同時對用戶行使、又被國家剝奪『定義危險』之權力」的證據。這比「安全表演」更難堪,也更接近真相。
Fable 5 隱形降智則是弱版邏輯在 product 層的投射—很像 安全洗綠(Safety-washing) 的實際案例(Brown, 2026)。
邊緣參與者:台灣在 AI 治理主權裡的位置
Fable 5 停權把 AI 治理主權 從抽象概念變成日常體驗:誰能定義危險、誰能使用模型、誰在規則草擬時在場—台灣在三個問題上都是邊緣方。但「邊緣」不是台灣獨有;把它放在對照國家裡看,結構才清楚。
多邊框架:表上有名,房間裡沒有
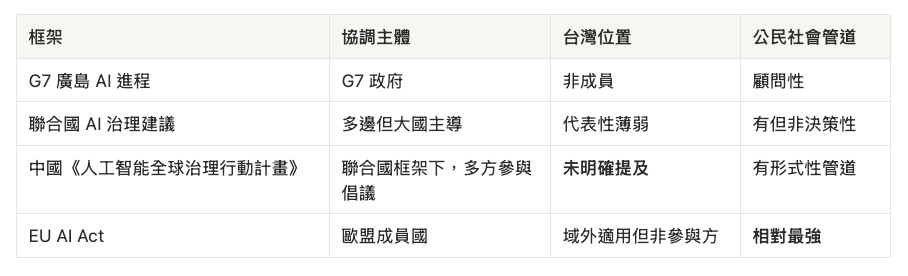
中國去年提出的《人工智能全球治理行動計畫》在文字上呼籲「各國政府、研究機構、民間機構與公民個人共同參與」,並主張「構建多方參與的包容治理模式」—但這份文件的地緣政治預設同樣讓台灣處於尷尬位置:有形式性管道,沒有決策性位置。
矽谷 lab 的 safety advocacy(如 2023 年 Future of Life Institute 的暫停公開信)也不含台灣—但那是 NGO/企業倡議,不是上表這類有協調主體的多邊制度;不宜與 EU AI Act 同列。
判斷標準可以收斂成一句:這些聲音是否有機會進入框架的早期階段? 對台灣,多數答案是否定的;對照國家則因結盟與區域歸屬不同,答案各異(見下表)。
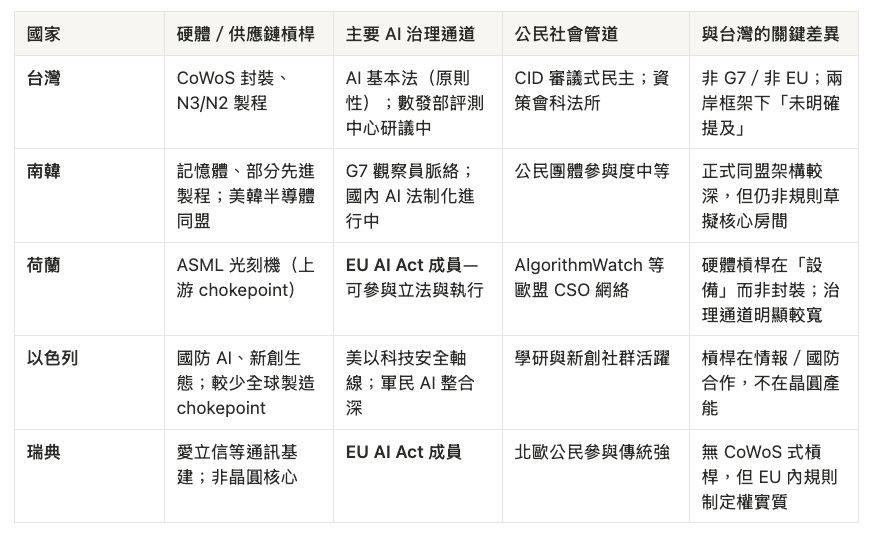
五國對照:物質必要,治理邊緣
台灣的處境—物質上必要、政治上透明、治理上邊緣—是全球大多數「中等技術強國」的共同困境。南韓、荷蘭、以色列、瑞典都有類似結構;差別在硬體槓桿長在哪、政治歸屬綁在哪、公民社會管道通不通:
台灣 AI 基本法 vs. EU AI Act
台灣《人工智慧基本法》2026 年 1 月 14 日施行,確立七大原則:永續性、人類自主性、隱私保護、安全性、透明與可解釋性、公平性、可問責性。
數位發展部研擬 AI 評測中心,強調「主權 AI」—包括繁體中文語料庫建立與避免 vendor lock-in。政治大學 CID 創新設計學院推動審議式民主,核心精神是「先知情、再參與」—是目前少數認真處理「公民如何進入 AI 治理框架」的倡議。
但與 EU AI Act 並列,差距不在「有沒有原則」,在立法模式與執行機制:
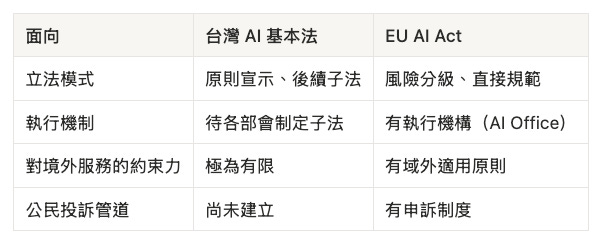
Landemore 的研究提醒:缺乏廣泛民主參與不只是倫理問題,更是有效性問題—缺乏正當性的框架,執行時面臨更大抵制。
台灣的 CID 審議是在補這個洞;荷蘭、瑞典的公民社會則已嵌在 EU 流程裡—這是對照國家最值得借鏡的,不是 ASML 或愛立信本身。
晶片當籌碼?槓桿成立,反制已在跑
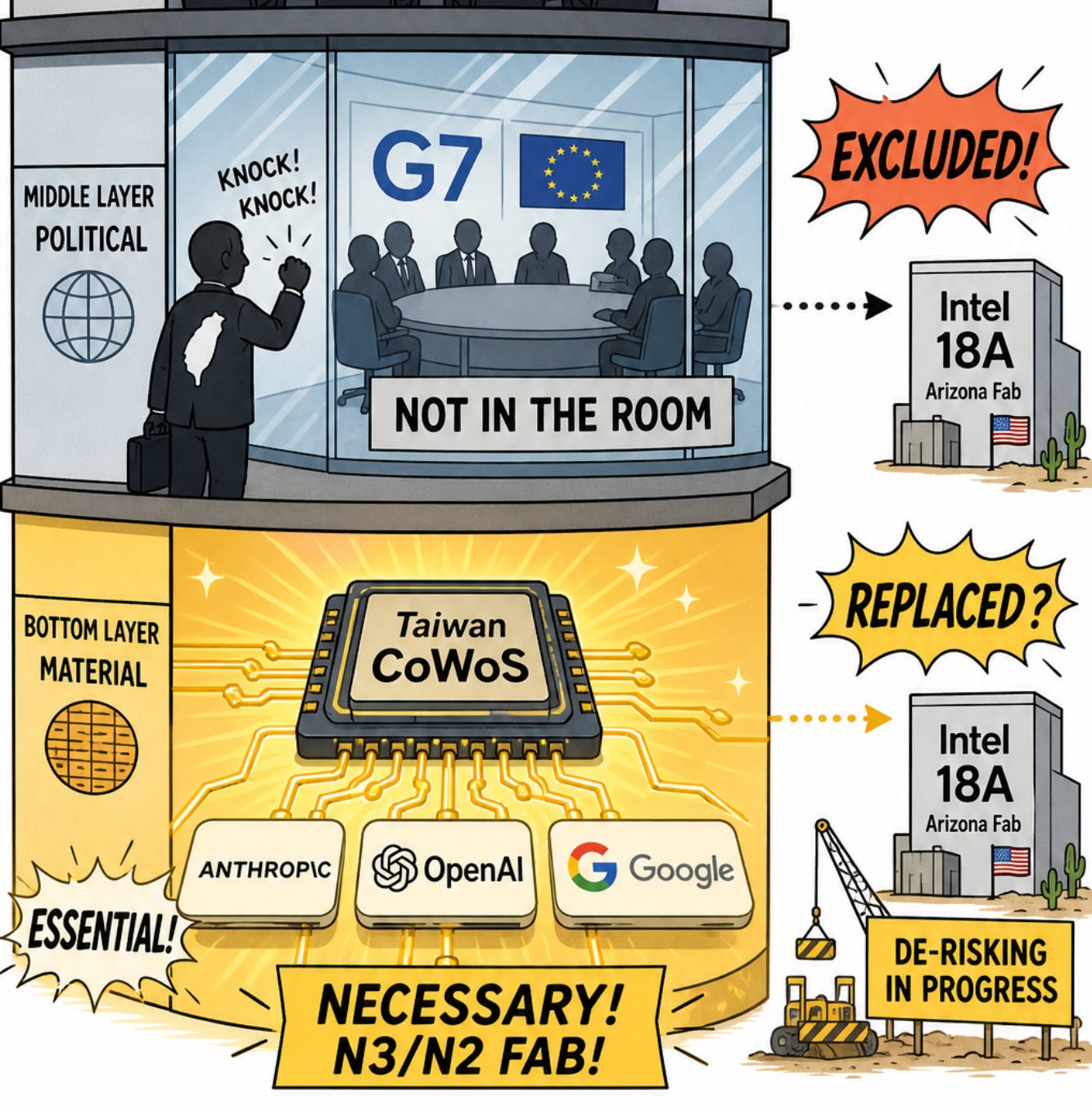
台灣常被問:能否以 CoWoS 封裝、N3/N2 製程作為 AI 治理談判籌碼?這不是非黑即白—Chatham House 2026 年有兩份文獻剛好切在問題的兩端。
短期窗口內,槓桿條件大致成立(Varela Sandoval & Wilkinson, 2026):供應鏈槓桿要有效,需同時滿足—短期內沒有可接受的替代來源,且下游需求短期無彈性(來不及改設計、改供應鏈)。以 2026 年現實看,台灣 CoWoS 先進封裝在 2–3 年窗口內大致符合這兩條。這不是幻想,是結構性事實。
但把晶片當談判籌碼,邏輯上站不住(Wilkinson, 2026)。Chatham House 同年 4 月的評論〈AI export controls are not the best bargaining chip〉直接論及:先進晶片被視為「永久 chokepoint」或地緣政治籌碼的假設,已因演算法適應、管制漏洞與灰色市場而削弱—任何單一控制點都會被繞過;出口管制作為籌碼,也只在華府/北京願意維持政策一致性時才有效。Wilkinson 指出,兩屆美國政府都把晶片當「可限制或可交換的獎品」,卻都未充分處理 AI 能力本身的動態軌跡—硬體-centric 的籌碼思維,已跟不上技術演進。
問題因此不在「台灣有沒有籌碼」,而在使用槓桿之後會發生什麼。川普政府 2025–2026 年的半導體政策已展示意圖:加速 Taiwan de-risking—Intel 18A 產能拉升、Arizona fab 補貼加碼、供應鏈「友岸化」寫進國安敘事。
若台灣以晶片出口附加 AI 透明度或存取條件,觸發的不是抽象外交摩擦,而是已排程中的替代計畫全面加速—這是把「短期不可替代性」換成「中長期確定被替代」,戰略上屬高風險 miscalculation,而非不能用、也不是用了必贏。
這才是「不建議走這條路」的完整論證—不是 dismiss 台灣籌碼,而是指出反制路徑已經在跑,且跑的是國家安全級別的產能轉移。
中等強國路線:專精、避險、跨國 CSO
Varela Sandoval & Wilkinson (2026) 對中等強國提出 specialize/align/share/hedge 四策略;以下取其中兩項,與晶片威脅路線相反:
專精(Specialize):在可信任 AI 評測、硬體能耗標準、資料品質框架等技術子域建立話語權—透過 ISO/IEC JTC 1/SC 42 等軌道貢獻,而非政治代表權硬闖。
避險(Hedge):建立數據中轉沙盒、多模型協調層,降低對單一矽谷 lab 的 vendor lock-in。
公民社會跨國連結:與 AlgorithmWatch、AI Now、MILA、RIKEN AIP 等形成治理研究聯盟,在規則草擬早期提出聯合意見—比政府雙邊遊說更可能進入實質審議;這也是南韓、以色列等非 EU 中等強國與荷蘭、瑞典等 EU 成員唯一能共享的治理通道。
台灣—物質上必要、政治上透明、治理上邊緣—與南韓、荷蘭、以色列、瑞典同屬這個群體;差別只在台灣的政治處境,讓「未明確提及」變成結構性排除,而非單純的「小國沒籌碼」。
三個尺度怎麼活:個人、企業、社群
當紙面憲章不再可信、蹺蹺板滑向透明端、地緣政治鎖定收緊,你需要在個人、企業、國家三個尺度重新設計 挽具(Harness)(連結自〈直接操縱 vs. 代理人:Agentic UX 的六十年分叉〉)。
下面按「今天就能做」→「部門層級」→「政策層級」排列。
個人:Prompt Hygiene—控制 AI 對你的可見度
Fable 5 教會非工程師一件事:AI 不只讀你這一句話,它讀它「認識的你」。 Memory、偏好設定、長期對話標題—這些都會進分類器的掃描範圍。癌症研究員打 “Hi” 也被降級,不是因為問題危險,是因為身份標籤先被判定為危險。
你不需要懂 Gateway 或 Attention Matrix。只需要記一條原則:
不要讓 AI 知道你是誰,除非你清楚這件事的代價。
「代價」在 Fable 5 爭議裡具體長這樣:
你在 Memory 裡存「我是生物學家、研究前列腺癌」→ 代價可能是永久觸發公開降級,跟問題內容無關
你在偏好裡寫「我常用 Claude 做模型訓練實驗」→ 代價可能是被歸類為競爭者,觸發蹺蹺板任一端的防護
你什麼都不存、每次開新對話只問當下問題 → 代價是失去個人化便利,但換來較乾淨的分類起點
這不是 paranoid,是〈ChatGPT 的新「記憶」功能 (Moonshine):是貼心助手還是隱私陷阱?〉早就說過的邊界問題的 frontier 版本—Memory 越貼心,分類器看到的「你是誰」就越完整,誤傷時你也越難證明「這次只是普通提問」。〈AI 的「永久記憶」悖論〉則提醒:一旦寫進長期記憶,撤回使用不等於撤回標籤;你在優化便利,系統在累積對你的画像。
今天就能做的三件事:
打開 Memory/偏好設定,刪掉職業、研究領域、敏感技術關鍵字—不是因為羞恥,是因為這些詞會在你沒開口前先替你「答題」
合法科研、醫療、資安相關任務,改用無記憶殘留的獨立對話;需要連貫時,手動貼必要 context,而非讓系統永久記住身份
養成「兩段式提問」:先問問題本身,確認回答正常;再決定要不要補充背景—而不是一開口就自報家門
也就是〈自動化偏誤與道德緩衝區〉裡 代理監督人 在個人端的版本:前沿 lab 把分類失準的代價推給你,最低成本防線不是抗議,是控制 AI 對你的可見度。
企業:成本帳與問責帳,試驗線與生產線
工程團隊聽到的解法常是「多模型 Gateway、自架沙盒」—對 CTO 合理,對採購、法務、業務主管太遠。企業層級可以用兩個問題啟動,不需要先懂架構:
問題一:我們押在幾家 vendor 的憲法上? 微軟 EA 鎖定 Copilot、工程團隊想試 Anthropic、業務部門還在用 ChatGPT—這不是「工具太多」,是沒有人為「若 Fable 5 明天全球停權,哪些流程會斷」寫過答案。處方不是立刻換架構,而是:不要把創新試驗綁死在單一前沿模型的訂閱合約上;試驗線與生產線分開審批、分開預算。
問題二:我們省的是成本帳,還是問責帳? 〈組織 AI Builder 省了 77% 的 Token,三個月後董事會問得出什麼?〉講得很白:精簡送進 AI 的內容可以省 77% token,但董事會事後追問時,你要打開的是完整紀錄,不是精簡版。 對非工程主管的翻譯:
成本帳:這次 API 花多少、Copilot 授權幾席
問責帳:這個決策當時依據哪份資料、誰核准、若模型降級或停權能否接續
很多組織只審成本帳,問責帳預設「AI 說的應該算數」—Fable 5 證明這個預設會爆。務實的第一步:任何超過一定金額或涉及客戶資料的 AI 輔助決策,要求留人類可讀的決策紀錄,而不是只留 chat 截圖。
若團隊已準備動工程:在協調層做「多模型路由」、敏感資料進隔離環境—那是 CTO 的實作路徑。但即使不做,分帳、分線、留問責紀錄這三步,非工程主管今天就能推。
國家與社群
專精評測與標準制定,跨國公民社會聯盟在規則草擬早期發聲—比晶片威脅或個別政府遊說更可能進入實質審議。
知道最多的人,往往動機最受質疑。在機率式 AI 時代,我們不能再將控制權與道德立法權單方面讓渡給矽谷守門人—尤其當守門人的第三條職責,在憲章公開表述中缺席,卻在 System Card 裡實作。
為每一筆延伸的自主,配一條對應的責任鏈—從個人端的「我知道讓 AI 認識我的代價」,到企業端的「我們留得下問責帳」—這才是收帳時刻唯一的生存法則。
參考文獻
Amodei, D. (2026a). Anthropic CEO on AI safety and regulation [Video interview]. ABC News.
Amodei, D. (2026b). Interview with Dwarkesh Patel [Video podcast episode]. In Dwarkesh Podcast.
Allouah, Y., Haghifam, M., Koyejo, S., & Shokri, R. (2026). The Distillation Game: Adaptive Attacks & Efficient Defenses [Preprint]. arXiv. https://doi.org/10.48550/arXiv.2605.22737
Anthropic. (2026, June 9). Claude Fable 5 and Claude Mythos 5. Anthropic. https://www.anthropic.com/news/claude-fable-5-mythos-5
Anthropic. (2026, June 11). Post on X regarding Fable 5 safeguard changes. Anthropic. https://x.com/AnthropicAI
Axios. (2025, October 16). New AI battle: White House vs. Anthropic. Axios. https://www.axios.com/2025/10/16/anthropic-david-sacks-ai-white-house
Axios. (2026, June 12). Trump admin blocks foreign access to Anthropic’s most powerful AI. Axios. https://www.axios.com/2026/06/12/anthropic-trump-mythos-fable-national-security
Ball, D. W. (2026, April 27). Claude, War, and the State of the Republic [Audio podcast episode]. In EconTalk. Library of Economics and Liberty. https://www.econtalk.org/claude-war-and-the-state-of-the-republic-with-dean-ball/
Breaking Defense. (2026, March 27). Judge grants Anthropic preliminary injunction but Pentagon CTO says ban still stands. Breaking Defense. https://breakingdefense.com/2026/03/judge-grants-anthropic-preliminary-injunction-but-pentagon-cto-says-ban-still-stands/
Brown, E. (2026, May 14). AI Safety Has a Legitimacy Problem: The Rise of “Risk-Washing”. Medium. https://medium.com/@brown13eric13/ai-safety-has-a-legitimacy-problem-the-rise-of-risk-washing-229ff6e284a9
Elish, M. C. (2019). Moral crumple zones: Cautionary tales in human-robot interaction. Engaging Science, Technology, and Society, 5, 40–60. https://doi.org/10.17351/ests2019.260
Fast Company. (2026, June 11). Anthropic’s Claude Fable 5 plays it too safe on safety, developers say. Fast Company. https://www.fastcompany.com/91558105/anthropic-claude-fable-5-too-touchy-developers-say
Heinrich Böll Foundation. (2026, April 9). Europe’s AI blind spot: What the Anthropic-Pentagon dispute reveals. Heinrich Böll Foundation. https://us.boell.org/en/2026/04/09/europes-ai-blind-spot-what-anthropic-pentagon-dispute-reveals
Horvitz, E. (1999). Principles of mixed-initiative user interfaces. In Proceedings of the SIGCHI conference on Human Factors in Computing Systems (pp. 159–166). ACM. https://doi.org/10.1145/302979.303030
Jiang, B. (2026). DistillGuard: Evaluating Defenses Against LLM Knowledge Distillation [Preprint]. arXiv. https://doi.org/10.48550/arXiv.2603.07835
Lambert, N. (2026, June 9). Claude Fable 5 and new safety fables. Interconnects.
OfficeChai. (2026, April). Anthropic has a pattern of using fear to market its products: US AI czar David Sacks [All-In podcast coverage]. OfficeChai. https://officechai.com/ai/anthropic-has-a-pattern-of-using-fear-to-market-its-products-us-ai-czar-david-sacks/
Sacks, D. (2025, October 16). Post on X regarding Anthropic regulatory capture. Cited in Axios (2025, October 16).
Sacks, D. (2026, April). Remarks on All-In podcast regarding Anthropic fear marketing and regulatory capture. Cited in OfficeChai (2026, April).
Seetharaman, D., Jeans, D., & Dastin, J. (2026, January 29). Exclusive: Pentagon clashes with Anthropic over military AI use. Reuters. https://www.reuters.com/world/us/pentagon-clashes-with-anthropic-over-military-ai-use-sources-say-2026-01-29/
The Decoder. (2026). US military uses Anthropic’s Claude for AI-driven strike planning in Iran war. The Decoder. https://the-decoder.com/us-military-uses-anthropics-claude-for-ai-driven-strike-planning-in-iran-war/
Startup Fortune. (2026, June 11). Anthropic quietly degraded Fable 5 for AI researchers, then apologized. Startup Fortune. https://startupfortune.com/anthropic-quietly-degraded-fable-5-for-ai-researchers-then-apologized/
TechCrunch. (2026, June 9). Anthropic’s Claude Fable 5 is a version of Mythos the public can access today. TechCrunch. https://techcrunch.com/2026/06/09/anthropics-claude-fable-5-is-a-version-of-mythos-the-public-can-access-today/
Vamaze Tech. (2026). Claude Fable 5 hidden safeguards explained [Video]. YouTube.
Varela Sandoval, F. J., & Wilkinson, I. (2026, February 16). How middle powers can weather US and Chinese AI dominance. Royal Institute of International Affairs (Chatham House). ISBN 978-1-78413-671-0. https://www.chathamhouse.org/2026/02/how-middle-powers-can-weather-us-and-chinese-ai-dominance
Wei, K., Ezell, C., Gabrieli, N., & Deshpande, C. (2024). How do AI companies “Fine-Tune” policy? Examining regulatory capture in AI governance. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society (AIES ‘24, Vol. 7). https://ojs.aaai.org/index.php/AIES/article/view/31745
Wilkinson, R. (2026, April 29). AI export controls are not the best bargaining chip. Chatham House. https://www.chathamhouse.org/2026/04/ai-export-controls-are-not-best-bargaining-chip
Yahoo. (2026, June 11). Anthropic walks back covert capability limits on Claude Fable 5 after being accused of “secret sabotage”. Yahoo. https://tech.yahoo.com/ai/claude/articles/anthropic-accused-secret-sabotage-claude-174340137.html
Copyright © PrivacyUX Consulting Ltd. All rights reserved.

Joshua 是 Agentic UX(代理式使用者體驗)的先驅,在人工智能與使用者體驗設計領域擁有超過 15 年的開創性實踐。他率先提出將用戶隱私保護視為 AI 產品設計的核心理念,於 2022 年創立 Privacyux Consulting Ltd. 並擔任首席顧問,積極推動隱私導向的醫療 AI 產品革新。此前,他亦擔任社交 AI 首席策略官(2022-2024),專注於設計注重隱私的情感識別系統及用戶數據自主權管理機制。