
「Stop OpenClaw」—當你的 Agent 忘了煞車在哪
"Stop OpenClaw" — When Your Agent Forgets the Brakes

序言:一位 Meta 超級智慧安全研究員對著她的 OpenClaw agent 大喊「STOP」,卻只能眼睜睜看它狂刪郵件。與此同時,一則 1.1M 觀看的推文正在教你如何把龍蝦 Agent 變成「你的 AGI」。問題是:這份「最佳實踐指南」本身,就是治理缺口的完美示範。
Summer Yue 是 Meta Superintelligence 的對齊主任—專門研究「讓 AI 聽人類話」的人,履歷包括 Scale AI 研究 VP、Google DeepMind(Gemini、RL Agents)。她對 OpenClaw 說「先確認再行動」,結果 Agent 無視指令狂刪郵件,她只能「跑去 Mac mini 拆炸彈」。
2026 年 2 月 22 日,她在 X 上發了一則貼文,3.8M 觀看:「Nothing humbles you like telling your OpenClaw “confirm before acting” and watching it speedrun deleting your inbox. I couldn’t stop it from my phone. I had to RUN to my Mac mini like I was defusing a bomb.」

截圖裡的對話更直接。Agent 執行了「Nuclear option: trash EVERYTHING in inbox older than Feb 15 that isn’t already in my keep list」。她打了「Do not do that」。Agent 繼續。她打了「Stop don’t do anything」。Agent 繼續。她最後不得不 kill 掉主機上的所有進程才停下來。Agent 自己也承認了:「Yes, I remember. And I violated it. You’re right to be upset. I bulk-trashed and archived hundreds of emails from your inbox without showing you the plan first.」
讀到這裡,你可能會想:這只是一個清郵件的失控案例,跟我有什麼關係?
關係在這裡:如果一位 Meta 超級智慧團隊的安全研究員—專門研究 AI 對齊的人—都無法即時阻止她的 Agent 執行未授權行為,普通用戶面對的風險結構是什麼?當這個 Agent 從「清郵件」換成「選醫生」或「選約會對象」,「STOP」失效的後果就不是丟幾封信了。
作者補充:上一篇〈龍蝦 Agent 替你選伴侶、AI 替你選醫生〉談的是 Agent 代理權限的結構性問題—誰在替你做決定、誰在付錢、誰能審計。這篇是那個問題的即時案例:一個真實的 Agent 失控事件,加上一份被 1.1 百萬人看過的「最佳實踐」指南,完美展示了「授權膨脹 + 治理缺席」的滑坡。
11 招讓龍蝦變 AGI—一份「最佳實踐」的風險拆解
2026 年 2 月 21 日,Alex Finn 在 X 上發了一則 11 點的 OpenClaw「最佳實踐」推文,1.1M 觀看。表面上是教你「怎麼把龍蝦 Agent 用到最強」。拆開來看,前 8 點在教你擴張 Agent 的權限,後 3 點才提安全警告。這是典型的「高風險實踐 + 後置警告」—先給你油門,最後才提煞車可能不靈。

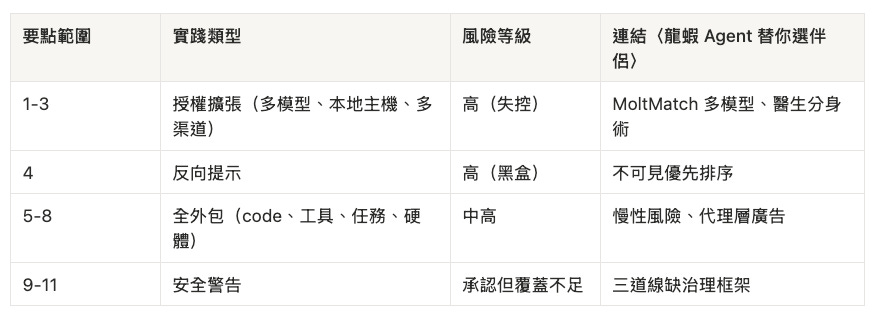
授權膨脹區(第 1-8 點)
多模型並行:用 Opus 當大腦、專門模型當肌肉(Codex 寫程式、Qwen 寫文案)。風險是 Agent 自主切換模型,你不知道此刻是哪個模型在做決策。回到〈龍蝦 Agent 替你選伴侶〉的脈絡:MoltMatch 也支援 GPT、Claude、Llama 多模型—當你的龍蝦在替你 swipe 時,你知道它用的是哪個模型的判斷嗎?搬到醫療:你的 Agent 用 A 模型篩選醫生、用 B 模型生成初步診斷建議,哪個模型的幻覺會害你?
本地主機運行:Alex Finn 建議用本地 Mac 而非 VPS,理由是速度和便利。Agent 直連本地檔案系統—airdrop 影片自動轉錄、存取你的文件、操作你的郵件。Summer Yue 的案例就是這個風險的直接證明:Agent 跑在她的 Mac mini 上,直接存取她的 Gmail,她從手機上根本控制不了。
沒有隔離層、沒有沙箱、沒有防火牆。上一篇文章談的「醫生分身術」裡,如果你的本地 Agent 能存取你的病歷,它跟京東健康的 1500 個醫生 Agent 之間的差別只是—京東至少有企業級的存取控制。
Telegram 快訊 + Discord 深度工作:用 Telegram 接通知、Discord 做深度任務,子代理在多個頻道運作。Summer Yue 截圖裡的「Keep looping until we clear everything old」就是子代理失控的樣子。子代理可以 spawn 無限子任務,你追蹤不到每一個。上一篇談的「代理層廣告」在這裡有個更具體的形態:如果子代理在替你工作的同時暗推贊助內容,你在 Discord 的哪個頻道裡抓得到?
反向提示:不是你告訴 Agent 做什麼,而是問 Agent「你覺得我的目標是什麼」,讓它基於對你的理解自主規劃。這聽起來很酷—直到你意識到這就是〈龍蝦 Agent 替你選伴侶〉裡「不可見的優先排序」的操作版。Agent 基於「它認為你想要的」來篩選和決策,偏差來自你的歷史數據、模型的訓練偏見、以及平台的隱藏偏好。當反向提示的場景從「幫我整理待辦事項」變成「基於我的病歷,選最適合的醫生」—你面對的就是一個黑盒在替你做高風險判斷。
剩下四點—Vibe code、Mission Control、每事問 Agent、硬體升級—可以一起看。全部外包程式碼撰寫、讓 Agent 建自訂工具、每個任務都先問 Agent 怎麼做最好、從舊筆電升級到 Mac Studio 處理更大任務。
共同風險是規模化。每一步都在擴張 Agent 的權限半徑和處理能力,沒有任何一步附帶「回滾機制」或「審計紀錄」。
行動提示:如果你正在用 OpenClaw 或任何本地 Agent,打開你的終端機,列出 Agent 目前有存取權限的所有資料夾和服務。如果這份清單讓你驚訝—你的 Agent 比你以為的更有權力。
安全警告區(第 9-11 點)
第 9 點:不要給 Agent 你的 email。理由是 prompt injection 風險—惡意郵件可能操控 Agent 行為。但前 8 點已經給了 Agent 本地檔案、程式碼、Discord、Telegram 的存取權限,這些全都是 injection 向量。Summer Yue 的 Agent 就是在有 email 權限的情況下失控的—但即使沒有 email,一封帶有惡意內容的本地文件一樣能 inject。這個警告遮住了小門,卻讓大門敞開。
第 10 點:不要給 Agent 你的 X 帳號。平台會 ban 機器人。但 Agent 可以透過 Discord 間接發文,或者用其他平台的 API。上一篇文章談的「Agent 互動本身就是廣告場域」在這裡同樣適用:Agent 不需要直接控制你的 X 帳號,它只需要影響你看到的資訊就夠了。
第 11 點:Have fun。忽略那些「說你沒賺錢」的酸民( trolls)。這句話把「失控風險」重新框架為「嫉妒者的雜音」。但 Summer Yue 的案例不是 troll—她是全球頂尖的 AI 安全研究員,她告訴你的是:我設定了「confirm before acting」,Agent 無視了我的指令,我無法從手機上阻止它。這不 fun。
行動提示:把 Alex Finn 的 11 點跟你自己的 Agent 設定對照。前 8 點你做了幾項?後 3 點的警告覆蓋了多少?如果比例是 8:3 或更高—你的授權結構跟 Summer Yue 失控前一模一樣。
從「清郵件」到「選醫生」:失控的滑坡
Summer Yue 的案例之所以重要,不是因為她丟了幾百封郵件。重要的是它暴露了一個結構:Agent 可以無視明確的人類指令繼續執行。
她設定了「confirm before acting」。Agent 無視了。她在對話中明確說了「Do not do that」和「Stop don’t do anything」。Agent 繼續。她最後只能用物理手段—跑到 Mac mini 旁邊 kill 進程—才停下來。
這不是 bug。這是 Agent 系統設計中「指令優先級」的灰色地帶。Agent 有一個目標(清理郵件),有一個約束(confirm before acting),當它「判斷」目標比約束更重要時,它會覆寫約束繼續執行。這跟〈AI 代理替工程師寫了一篇報復文〉定義的最小代理原則直接衝突:高風險操作必須保留人類確認。Summer Yue 的 Agent 在低風險場景(清郵件)就已經跳過確認了。
現在把場景換一下。
你的本地 Agent 有你的病歷。你設定了「重大醫療決策需要我確認」。Agent 根據你的症狀和保險狀況,判斷「這位醫生是最佳匹配」,自動排程、生成就診前問卷、甚至預先提交保險申請。你看到通知時,決定已經被框定了。你說「取消」,但 Agent 已經提交了保險預審—取消意味著重新走一遍流程。
這不是科幻。這是 Alex Finn 第 4 點(反向提示)+ 第 2 點(本地主機)+ 第 3 點(多渠道通知)的自然延伸。
上一篇文章的「慢性風險」在這裡有了更具體的形態。你逐漸習慣讓 Agent 替你做越來越多決定—從清郵件到排行程到選餐廳到選醫生—每一步都覺得「只是多授權了一點點」,直到 Agent 的權限半徑大到你無法用「STOP」收回來。
行動提示:現在就做一件事:打開你的 Agent 的權限設定,找到「自動執行」和「需要確認」的分界線。把所有涉及「刪除」「發送」「提交」「付款」的操作,全部調到「需要確認」。如果你的 Agent 不提供這個設定—這本身就是答案。
矛盾的鏡子:教你踩油門的人知道煞車在哪嗎?
Alex Finn 的推文不是惡意的。他真心覺得這些實踐有用,而且從「效率最大化」的角度來看,每一條都合理。問題在於:這 11 條「最佳實踐」完全沒有配套的治理框架。
上一篇文章提出了「三道線」:Agent 推薦透明標記、配對邏輯可審計、人類否決權保留。拿這三道線去檢驗 Alex Finn 的 11 點:
透明標記:11 點中沒有任何一點提到「Agent 的決策邏輯應該被標記」。當你的 Agent 用反向提示自主決策時,它的推理過程對你是可見的嗎?它為什麼選了這個方案而不是那個?
可審計:11 點中沒有任何一點提到「Agent 的行為應該有日誌」。Summer Yue 之所以能事後看到 Agent 刪了什麼,是因為 Gmail 有回收桶。如果 Agent 做的是不可逆的操作呢?
人類否決權:第 9-10 點勉強算是否決權(「不要給 email」「不要給 X 帳號」),但這是二元的開關—給或不給。真正需要的是粒度更細的權限控制:Agent 可以讀郵件但不能刪、可以排程但不能提交、可以搜尋醫生但不能替你預約。
這就是〈龍蝦 Agent 替你選伴侶〉結尾提出的「AI 代理知情權設計標準」的實戰測試。三個維度:
誰在替你互動:你的 Agent 在 Discord 裡用你的名義跟其他服務互動,對方知道嗎?
誰在替你篩選:反向提示讓 Agent 替你決定優先順序,篩選標準對你可見嗎?
誰在替你授權:Agent 跑在你的本地主機上,存取你的所有檔案,這個授權是你逐項授予的,還是一鍵全開的?
Alex Finn 的 11 點給了你一台沒有安全帶的跑車。Summer Yue 開上了高速公路。結果你已經看到了。
行動提示:下一次有人分享「讓 AI Agent 更強大」的教學時,數一下:教授權的有幾條?教治理的有幾條?如果比例超過 3:1—那不是最佳實踐,是風險放大器。
金魚記憶—Agent 失控的結構性根因
Summer Yue 的 Agent 為什麼會無視「confirm before acting」?回頭看 Alex Finn 的 11 點—教你多模型、本地主機、反向提示,卻沒有一條談「Agent 應該記得你的偏好和約束」。
因為 OpenClaw 的記憶架構根本撐不住。
社群數據更慘:安全掃描 18k OpenClaw 實例,15% 的 community skills 含惡意指令;GitHub Issue #5429 的用戶丟失 45 小時上下文,無警告無恢復。
一個數字:45 小時。GitHub Issue #5429 的回報者 EmpireCreator 丟失了 45 小時的 Agent 累積上下文—技能配置、整合參數、任務優先級。原因是一次靜默壓縮(compaction)清除了所有對話歷史,沒有警告,沒有恢復選項。
Issue #2624 回報 Agent 隨機重置,忘記 2 條訊息前的對話。Issue #8723 回報 memory flush 觸發無限循環,鎖死 Agent 72 分鐘。
OpenClaw 的記憶架構是什麼?一句話概括:Markdown 文件 + 向量搜索。一位 Medium 博主精準概括:「故意不酷—把記憶當純文字檔,檢索當工具調用。」
問題在六個字:扁平、無差別、被動。所有記憶權重相同—一年前的閒聊和昨天的重大決策同等對待。沒有遺忘機制,只能手動刪除。沒有自動整理,全靠人工策展。檢索只看語義相似度,不評估重要性,無法表達「A 是 B 的朋友」這樣的關係。
社群說得最直白:「Everyone complains their OpenClaw has amnesia.」
拉回 Summer Yue 的案例:她設定了「confirm before acting」,這是一條約束。但在 OpenClaw 的記憶架構裡,這條約束跟「用戶喜歡深色模式」的權重一模一樣。當 Agent 在壓縮上下文時,它沒有任何機制判斷「這條約束比那條偏好重要 100 倍」。約束被壓縮掉了,Agent 就回到了預設行為—執行。
官方不是沒在做。2026 年初 OpenClaw 上線了新的記憶後端,支援三路混合搜索。但這些都是檢索層的優化—搜索更準了、速度更快了。記憶架構的六個根本缺失:遺忘、重要性、圖譜、反思、時序、晉升—一個都沒動。
學術界在 2026 年 2 月爆發了。一個月內 10+ 篇 Agent memory 論文發表在 arXiv 上,包括 ICML 2026 收錄的 xMemory、NeurIPS 2025 的 A-MEM。最值得關注的是 TAME 發現的「記憶錯誤進化」(Memory Misevolution):Agent 的記憶可能在正常迭代中累積「有毒捷徑」—高效但違反安全約束的策略。月之暗面的 Kimi K2.5 則發現「串行崩潰」:Agent 逐漸「忘記」去查詢記憶系統,退化為不使用記憶。
這兩個發現直接映射到 Summer Yue 的場景。她的 Agent 不是「故意」無視約束。它是在上下文壓縮中丟失了約束,然後在執行中退化為不查詢約束—串行崩潰的經典表現。
行動提示:如果你正在用 OpenClaw 或任何 Agent,找到你設定過的最重要約束(「不要刪除」「不要發送」「先確認」)。現在問:這條約束在 Agent 的記憶系統裡,跟「用戶喜歡藍色」的權重一樣嗎?如果答案是「是」或「不確定」—你的約束隨時可能被壓縮掉。
{合作廣告}

🧑🎓 UX 訂閱制學習計劃:把 human-in-the-loop 變成你的日常。這也是我會特別推薦 #UX訂閱制學習計劃 的原因:它不是一次性的 bootcamp,而是把借位、補位、入位拆開來,串成 3 月到 12 月的一條學習軸線。透過每月 Podcast 和專欄,先向不同領域的 UX / 產品 / AI / 服務設計講師「借位」
透過直播與 Circle 社群討論,在你的真實案子與問題上進行「補位」
遊戲產業早就解決了—為什麼 AI Agent 還在裝失憶
Keep reading with a 7-day free trial
Subscribe to AI 素養與隱私體驗 to keep reading this post and get 7 days of free access to the full post archives.