
[讀者回函]「從 Markdown 切換到 HTML」,不如說:溝通給人看 → 用 HTML;建立可被 agent 引用的知識 → 用 structured text/markdown

一篇好文章為何容易被誤讀
Thariq Shihipa 的心得思路。它真誠、有實例、有截圖、有可重現的 prompt 範本,而且作者是 Anthropic 內部人,立場本身就是一手資料。但它在簡體圈被轉譯的標題「Claude 工程師逃離 Markdown:用一晚把工作流全換成 HTML」就出了個小問題—把一個關於輸出形式的設計選擇,包裝成了關於儲存格式的時代斷代。

這個包裝產生了具體後果:我這週收到的訊息至少有三波是「你之前推的 markdown 工作流是不是已經過時了?」「要不要趕快把 wiki 改成 HTML?」「Anthropic 自己人都這樣說了。」
要回答這些問題不需要否定 Thariq—他文章裡寫的東西大多是對的。真正要做的工作,是把他沒有顯式區分、但他自己其實一直在實踐的那個區分挖出來:substrate 層 vs view 層、儲存格式 vs 呈現格式、工廠 vs 成品。把這層區分挖出來之後,這篇文章不但不挑戰 markdown 為主的 AI/UX 工作流,反而證實了它。
Thariq 在文中親手畫出了那條線
我從他文中挑兩處他自己的承認。
第一處在 FAQ 段,「版本控制怎麼辦?」
他寫:「老實說,這是 HTML 最大的缺點之一。和 Markdown 相比,HTML diff 噪音很大,也很難審查。」這句話是文章裡最被略讀的一句,因為它出現在 FAQ 末尾、語氣是「對對對我知道」式的順帶承認。
但這句話的意思很重:版本控制是知識資產長期累積的核心紀律。如果 HTML 的 diff 噪音大、難審查,那意思是任何「會被多人修改、會跨時間累積、會被回頭追問『為什麼當初這樣決定』」的內容,都不該以 HTML 為主要儲存格式。
第二處在「數據攝取」段,他描述 Claude Code 能讀什麼
原文:「除了文件系統,Claude Code 還可以通過你的 MCP(比如 Slack、Linear 等)、你的網頁瀏覽器(通過 Chrome 裡的 Claude)、你的 git 歷史等方式找到更多上下文。」
注意他列舉的素材清單:程式碼檔案、git history、Slack 訊息、Linear ticket、瀏覽器內容。沒有一項是 HTML 檔。HTML 在他的工作流裡,是 agent 寫出來的產出,不是 agent 讀進去的素材。
素材端是程式碼(純文字)、git diff(純文字)、Slack(純文字)、Linear(結構化純文字)—這些全是「機器易讀、人類易讀、diff 友善」的格式,本質上就是 markdown 譜系的東西。

把這兩處放一起看,Thariq 自己其實已經畫好了那條線:
HTML 適合「給人看一次」的東西:報告、PR 描述、mockup、互動原型、spec 文件最終呈現版
Markdown / 純文字 適合「會被機器與人類反覆讀寫」的東西:codebase、git history、wiki page、persona、scenario、decision log、acceptance criteria
他沒明說的是:這兩件事不是替代關係,是工序關係。view 層的好看 HTML,是 substrate 層的紮實 markdown 生出來的。
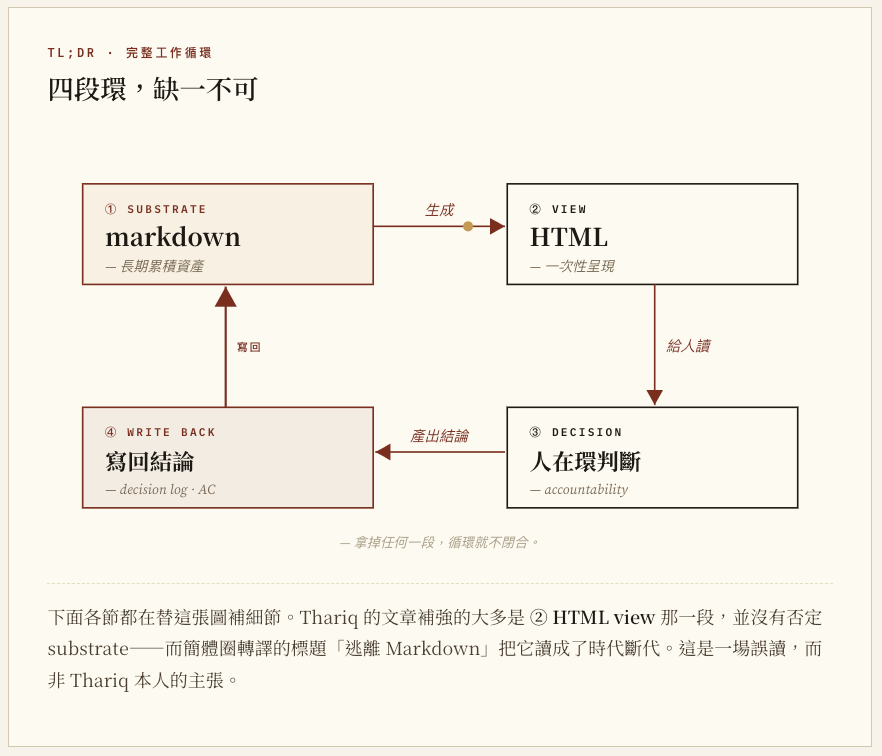
先把後面全文要扣住的那張圖說在前面:完整工作循環只有四段—markdown substrate ↔ HTML view ↔ 設計師決策 ↔ 寫回 markdown substrate。下面各節都是在替這張圖補細節;Thariq 文章補強的大多是 HTML view 那一段,並沒有否定 substrate。
信息密度的真正意涵:HTML 是輸出的天花板,不是輸入的優勢
(對照第二節那張四段環:這一小節專門補循環「左側」—長期資產的 substrate 該長什麼樣子,才不會在吃進 agent 協作後發散成 HTML 特有的命名漂移。)
Thariq 對「信息密度」的論證是文章最強的一段。他列舉 HTML 能表達的東西:表格資料、CSS 設計、SVG 插畫、可執行 script、互動元件、空間排版、嵌入圖片。他說「Claude 能讀取的信息集合裡,幾乎沒有什麼是不能用 HTML 相當高效地表示出來的」。
這個觀察是對的,但結論需要校準。HTML 是輸出表達的天花板,因為它能容納所有人類消費的格式。但這恰恰意味著它不是輸入儲存的優勢—任何能容納一切的容器,本身的結構約束就最弱。
還有一道常被忽略的「技術性偏心」:主流 LLM 的訓練語料仍以 markdown、純文字與類程式碼格式為大宗,而非瀏覽器 DOM。因此當你要 agent 生成、比對、批評、重寫同一份規格時,那份東西若以 markdown substrate 維護,語義對齊與長程連貫通常比要模型在 HTML 標籤層級上推理來得穩。
HTML 為渲染與版面而生;structured text/markdown 同時對人類編輯與模型讀寫都比較「對齊介面」。這不是要宣稱模型讀不懂 HTML—而是:在公開訓練語料的常見配比下,substrate 選 markdown/frontmatter 常有額外的語義穩定性。
舉個具體例子。假設我要儲存「使用者通知偏好」這個概念,它要被:
設計師寫入(描述設計意圖、權衡考量)
Auditor agent 讀取(檢查是否違反 dark pattern)
工程師讀取(轉換成程式碼實作)
三個月後的新進設計師讀取(理解為什麼這樣決定)
一年後的 PM 讀取(思考要不要改)
Git 追蹤(誰在什麼時候改了什麼、原因是什麼)
如果用 markdown + YAML frontmatter:
---
type: decision
id: d-2026-04-default-digest
applies_to: [sarah-busy-parent]
trade_off: 損失即時性,換取留存率
overrides: ios-default-immediate
---
# 預設模式:digest 而非 immediate
Sarah 類型使用者一旦被 immediate 模式打擾過頭,會直接關閉所有通知...
這份檔案 6 個月後被 5 個人輪流讀寫,每次 commit 的 diff 都會清楚顯示「誰改了什麼欄位」「誰補了哪段論述」。Auditor agent 可以結構化地查詢 frontmatter—重點不只在「機器能不能 parse」,而在 key 集合被規格鎖住、變更可被 review:同樣的查詢在半年後仍能指向同一組語意。
如果同樣的內容用 HTML:
<article class="decision" data-id="d-2026-04-default-digest">
<header>
<h1>預設模式:digest 而非 immediate</h1>
<div class="meta">
<span class="applies-to">Sarah-busy-parent</span>
<span class="trade-off">損失即時性,換取留存率</span>
</div>
</header>
<section class="body">
<p>Sarah 類型使用者一旦被 immediate 模式打擾過頭...</p>
</section>
</article>
第一次寫的時候差別不大,甚至從「單機、單 agent 可不可以解析結構」來看:**data-*、class、meta div 與 YAML frontmatter 一樣都是結構化文字**,Auditor 讀這層並不必然比讀 YAML 困難。真正的風險出在多人協作時 HTML 的典型寫作法:多半沒有 schema 強制、欄位約束只靠慣例,人類手上的命名會發散,querySelector/模板假設會隨任一人的重構悄聲斷裂。
YAML frontmatter 至少有一條可用的收口路徑:固定 key、PR review、yaml schema、lint—HTML 要等價地做同樣的紀律,成本通常更高。
5 個人輪流改 6 個月之後,你看到的往往是:
有人會用
<span>包,有人用<div>,有人乾脆放屬性class 命名會漂移(
applies-to/appliesTo/applies_to)有人會用
<section>巢狀包另一個<section>加層次一個人忘了關
</article>,整個檔渲染就壞了Git diff 出來:每行都動,因為縮排、屬性順序、tag 嵌套深度全部洗牌
Auditor agent(或下游腳本)對「欄位路徑」的依賴變脆—不是因為看不懂 attribute,而是路徑所指向的人類約定不再穩定
這不是 HTML 不好,是 HTML 容器太寬鬆。在缺乏 schema/lint/review 紀律時,它的「信息密度」會變成「命名與結構可被任意改寫的空間」,協作規模一上來就混入噪音。Markdown + frontmatter 結構先天較窄—能寫的版型少,但欄位比較容易彼此一致。
Thariq 在文章裡也提了個微妙的細節:他自己「frontend design plugin 可以幫助 Claude 製作好的 HTML 文件」。為什麼需要 plugin?因為沒有 plugin 的話,Claude 生出的 HTML 風格漂移嚴重。這個 plugin 就是在補 HTML 缺乏內建約束的洞—而 markdown 不太需要這種東西。
「我不太讀超過 100 行的 Markdown 了」這句話的重點
(對照四段環:Thariq 這段自述,多半落在「view/單次閱讀」那一側的流程體驗—不是論證整個組織都該拆掉 substrate。)
Thariq 文章的個人動機這段我覺得寫得最誠實:
「我也越來越少親自編輯這些文件,而是把它們當作規格文檔、參考文件、頭腦風暴輸出等等。當我確實要修改時,通常也是提示 Claude 去改;這就削弱了 Markdown 最大的優勢之一。」
「實際使用中,我發現自己往往不會真的閱讀超過 100 行的 Markdown 文件;更不用說讓我組織里的其他人去讀了。」
這兩句話講的不是 markdown 的失敗,講的是 Thariq 的工作流變了。他正在做的事情是:用 AI 大量生成計畫文件、規格、探索、報告,然後自己當讀者(或他的同事當讀者),++很少改、改也丟給 Claude 改++。
這個工作流下,markdown 確實在喪失優勢—因為 markdown 的優勢是「人類也容易寫、機器也容易讀、diff 友善、版本控制乾淨」。如果你不寫了、不版本控制了、只生成跟閱讀,那 markdown 就只剩下「人類也容易讀」這一條優勢,而這條優勢正好被 HTML 用「視覺清晰、可互動、可嵌入圖表」打敗。
但反過來想:如果你的工作流是「會反覆寫、會多人協作、會跨時間追蹤」呢? 設計師的 wiki 屬於哪一類?
我的觀察是混合的。(對照四段環:以下兩串清單在切—哪些內容本質上要留在左側、累積成資產;哪些適合先做 HTML view,再決定什麼值得寫回去。)
Wiki 內容裡有些東西本質上是「會被多人反覆讀寫」的長期資產:
persona 會隨研究更新
decision log 會持續累積
design system tokens 會迭代
scenario 會被多個 feature 引用
acceptance criteria 會被 Red Team 反覆審視
這些東西如果存 HTML,6 個月後 diff 會是惡夢。
Wiki 也有些東西本質上是「一次性生成、給人看一次」:
給領導層的功能進度報告
給工程的 spec handoff 文件
給跨部門的 demo presentation
sprint retrospective summary
feature 上線後的影響分析
這裡的「一次性」指的是報告的呈現載體(常以單檔 HTML 生成、閱畢封存),不是說 retro 的思考可以丟進抽屜。行動項目、承諾、風險與決策必須回寫 substrate(例如 decision log、tickets、下一次 sprint 的對照條款),不然 wiki 會變成只有 view、沒有累積的殼。
這些東西生成出來給人看完就歸檔,HTML 確實比 markdown 好—因為有顏色、有圖、有互動、有移動端適配。(但別忘了注腳:該留存的不是 HTML 檔本身,是可被追問的紀錄。)
所以正確的問題不是「我們該用 markdown 還是 HTML」,是「這份內容會被反覆讀寫,還是一次性消費?」答案決定格式。
工序而非斷代:一個具體流程
先把反方推到最強,再來談為什麼我仍會堅持 substrate:在純機器閉環的 agent 管道裡,agent 產 HTML 的速度與品質已經夠好用;版本的痛苦也有人主張可以用 snapshot + semantic diff/結構化比對工具接住,不一定要人類徒手讀 unified diff。這在「沒人要為決策署名、沒人要向組織解釋取捨」的前提下,確實越來越可行—2026 年的現實是,很多一次性產出真的可以交給閉環處理。
設計與產品相關工作流的缺口在另一個詞:accountability。PM、設計師、法遵、利害關係人要回答的是「為什麼這版比上一版更值得信賴/為什麼風險被接受」,不是「這兩個 HTML snapshot 結構上等價」。人類要的往往是可稽核敘事(論據鏈、權衡、誰在最後簽了什麼)與可追溯 diff—這類責任仍然黏在可被集體編輯、可被 PR review 的文字 substrate 上好承載。換句話說:機器閉環可以做得很好;但凡工作產物要進組織記憶、要接受跨職能質詢,就還有一道不能省略的人在環。Thariq 自己在 FAQ 承認 HTML diff/審閱的痛,那根刺正好扎在這條線上。
把 substrate / view 分層落地,AI/UX 實作流程會變成這樣(若以 HTML 版呈現這篇文章,下面這張圖很值得直接做成可點的流程元件—用文字獨白三道工序反而有種自我反題式的幽默):
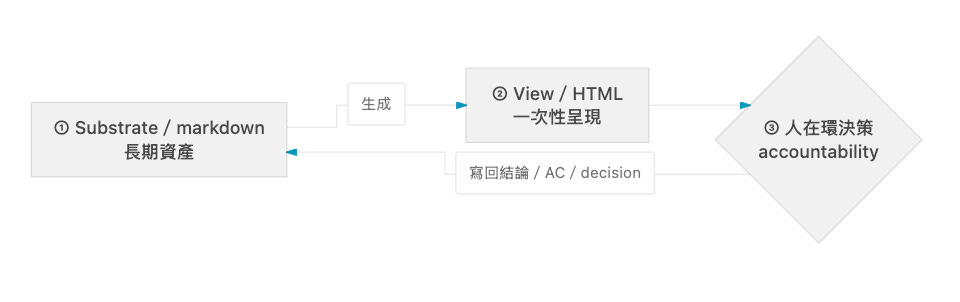
第一道工序 · Substrate 累積(markdown)
設計師在 IDE 裡用 markdown 寫 persona、scenario、page list、decision、AC。每份檔案有 frontmatter 標明 type、id、relations、status。Git 追蹤所有變更。Agent 從這層讀取上下文做生成、審計、跨檔交叉引用。
這層的紀律是:schema 嚴格、命名收斂、diff 乾淨、可長期累積。它存活的時間是++產品的整個生命週期++。
第二道工序 · View 生成(HTML / SVG / 互動原型)
當設計師要做 mockup、要做 PR 描述、要做給領導的報告、要做客戶 demo—這時候命令 agent 從 substrate 讀取相關片段,生成 HTML。這份 HTML 可能包含:
從 persona markdown 摘出來的使用者畫像視覺卡片
從 decision log 抓出來的時序動畫
從 page list 渲染出來的 sitemap 圖
從 AC 列表渲染出來的驗收測試打勾介面
從 token JSON 生成出來的配色方案展示
這份 HTML 是一次性產出。看完、用完、決策完就歸檔—下次需要相似的東西就重新生成,而不是維護它。
這層的紀律是:好看、清楚、互動友善、易分享。它存活的時間是++單次決策的視窗++。
第三道工序 · 回饋寫回 substrate(markdown)
HTML 看完做了決策—「我們選方案 B」「Auditor 發現 5 個問題、修 3 個、接受 2 個」「跨部門對齊了 deadline」—這些結論要寫回 markdown substrate 層。原本的 HTML 報告本身可以歸檔,但決策的本體要回到 wiki,因為它會被未來的人查、被未來的 agent 引用、被未來的工程實作參照。
這個三道工序的流程裡,markdown 跟 HTML 都有位置,但位置不可互換。把 substrate 換成 HTML 等於拆掉資產累積機制;把 view 強制鎖在 markdown 等於放棄好的呈現。Thariq 文中所有具體 use case—spec 文件、PR 描述、研究報告、設計探索、報告 dashboard、編輯介面—全部是 view 層的事。他沒講的是這些 view 從哪裡來、決策怎麼回去。
從工程的角度再驗證一次
(仍是那張環:這一節把「左側」拉寬到其他工程資產,論證不是設計師特例。)
跳出設計領域看更廣的工程實踐。所有經得起時間考驗的工程資產儲存格式都有一個共通特徵—它們是純文字、有強 schema、diff 友善:
程式碼是純文字
配置檔是 YAML / TOML / JSON
基礎設施是 Terraform HCL
資料庫 schema 是 SQL migration
API 規格是 OpenAPI YAML
CI/CD pipeline 是 YAML
文件是 Markdown
學術論文是 LaTeX(純文字)
HTML 在這個列表裡有什麼位置?它是渲染輸出—是 markdown 文件渲染後的網頁、是 OpenAPI 跑出來的 swagger UI、是 Terraform plan 的視覺化、是 codebase 用 mkdocs 跑出來的文件站。它沒有以「儲存格式」身份出現在任何資產積累流程裡。
這不是巧合。長期資產需要結構約束,而結構約束的成本是「能寫的東西比較少」—這個成本在系統規模變大、時間拉長後會反過來變成優勢。HTML 的優勢「能寫的東西很多」在規模變大時會反過來變成 chaos。
Thariq 文章開頭講「Markdown 時代把 AI 當會寫長文檔的實習生」「HTML 時代把 AI 當能幫你搭產品級工作介面的搭檔」這個比喻很漂亮,但比喻有它的限制。實習生跟搭檔不是對立的—你需要實習生整理資料、需要搭檔做漂亮報告,這是兩個工作位置,不是兩個時代。
{合作廣告}

🧑🎓 UX 訂閱制學習計劃:把 human-in-the-loop 變成你的日常。這也是我會特別推薦 #UX訂閱制學習計劃 的原因:它不是一次性的 bootcamp,而是把借位、補位、入位拆開來,串成 3 月到 12 月的一條學習軸線。透過每月 Podcast 和專欄,先向不同領域的 UX / 產品 / AI / 服務設計講師「借位」
透過直播與 Circle 社群討論,在你的真實案子與問題上進行「補位」
對 AI/UX 實作的具體建議
如果你正在建立或重構 AI/UX 工作流,下面是我會給的五條建議:
