
[讀者回函] LLM 的盲點將現:世界模型與 AI-UX 轉型的流程策略
The LLM Blind Spot: Your Strategic Guide to World Models and AI-UX Transformation

你現在手上的 AI 產品,幾乎都綁在 LLM 上:對話、生成、總結樣樣來。但你越用越心虛
模型懂字、不懂世界;
一旦離開聊天框,進到真實介面和流程,就開始亂講、亂引導;
團隊只會寫 prompt,不會設計「AI 真的看得懂的 UI 世界」。
你其實不是在問「要不要跟 LeCun 站在一起反 LLM」,而是在問: 「如果世界模型真的來了,我現在這條 LLM 路線會不會變成技術債?」
深度學習教父 Yann LeCun 直言不諱:「如果只透過文本訓練,我們絕對不可能達到人類級別的 AI,這永遠不會發生。」LeCun 的挑釁式論斷,不一定都對,但提醒我們一個事實:只靠文字,很難讓 AI 真的「看到」世界。曾被問及為何年屆 65 歲仍不退休,他堅定地回答:「因為我有一個使命。我一直認為,無論是讓人們變得更聰明,還是透過機器讓人們更具智慧,增加世界的智慧含量本身就是一件好事。」
對他而言,真正的研究,是開放、透明的:「在我看來,除非你發表你的工作,否則你不能稱之為研究,因為否則你很容易被自己愚弄。」這種「逆流而上」的姿態,不僅定義了他身為卷積神經網絡(CNN)發明者、PyTorch 發展推手、圖靈獎得主的傳奇地位,更劃清了他在 AI 發展道路上的鮮明立場。LeCun 不相信一個模型需要重現現實中的每一個細節,他強調:「一個模型需要重現現實中每一個細節的想法是錯誤且有害的。」他更看重抽象化與對真實世界的根本理解。
在你現有 AI-UX 工具上,多走半步
如果把現在團隊的 AI 能力盤點一下,你大概會發現這種圖景:
Figma Make / First Draft:幫你生成 wireframe、元件、UX copy。
Relume:幫你 60 秒生出整站 sitemap 和 wireframe,然後一鍵丟回 Figma / Webflow。[8]
MagicPattern:幫你生 hero 圖、背景 pattern、視覺素材。
UXPilot / MagicPath:幫你用 LLM 腳本化 persona、user flow、對話文案。
Mobbin:幫你查到「別人怎麼做這個 flow」,從 30 萬+真實畫面裡抄對的 pattern。[2]
它們都很有用,但全部停留在「靜態產出」這一層:畫面、文案、流程圖。真正的風險在於:沒有任何一個工具在幫你回答——「使用者實際點完這些畫面之後,AI 看到的是什麼世界?」
精準診斷:LLM 智能助理的導航困局
你可能也遇過這種場景。根據 Nielsen Norman Group 2020 年的大規模可用性研究,Siri、Alexa、Google Assistant 在複雜任務上的失敗率高達 60% 以上。
一個典型的失敗案例:用戶告訴 Siri「在休斯頓,現在天氣怎樣?」它能理解;但如果改成「現在在休斯頓天氣怎樣?」,Siri 會在「現在」就截斷對話,然後說需要打開位置服務。
更嚴重的是:Google Assistant 有時會誤觸跳轉到其他 skill(應用)。一個用戶請求「前往 Moss Beach 的路線」後,Google Assistant 說「你可以用 Solar Flair…」然後直接進入了一個陌生的 UV Index 預報應用。用戶完全被搞懵。
問題的本質是什麼?LLM 型的語音助理完全看不到螢幕、看不到使用者目前在哪個介面,只能「猜測」。它能回答文字問題,卻對「你現在的世界狀態是什麼」一無所知。所以即使回答對了,也常常無法提供符合螢幕上下文的指引。
這正是你現在的痛點:你的智能產品能講話,卻看不見世界。
處方一:你要不要押世界模型?先看「風險結構」
對你來說,風險不是「AI 技術錯了」,而是「路線錯了」。如果你只押 LLM,三年後會遇到三種結構性風險:
模型只能在聊天框裡發揮,離開文字就失能(物理、介面、流程全看不懂)。LeCun 說:「LLM 完全不擅長處理高維度、連續且嘈雜的模態數據。」[4]
安全與隱私只能靠輸出過濾,沒有「預測後果、內建約束」的規劃能力。他強調,AI 系統必須「透過內建約束來保證其行為不會危及任何人或產生負面副作用。」[4]
團隊全部訓練在 prompt/文案上,沒有人會設計「AI 看得懂的世界」。這會讓你在需要多模態感知時,完全沒有內部 seed 團隊可以接。
押世界模型也不是免費的勝利。短期內,你會多背兩種風險:
資料側:你能不能拿到足夠乾淨的螢幕序列來訓練?
架構側:你的 UI 和後端管線,有沒有乾淨的狀態定義可以對齊?
換句話說,這不是「拋棄 LLM 換世界模型」,而是「在現有 LLM 堆一層感知與狀態結構」,你仍然要算成本。
處方二:具體怎麼落地 UI-JEPA 思路?對齊你已經在用的工具
如果你要在現有 LLM 產品裡,補上一層「世界模型」,可以直接照這個三層結構想:
第 1 層:界面感知層(UI-JEPA 類)
輸入:螢幕錄影+互動事件。
任務:把「亂七八糟的畫面」壓成少量抽象狀態(目前在哪個頁面、任務走到哪一步)。
典型 owner:前端/資料工程+ ML
工具對照版:用 Relume / Figma 先產出 sitemap 和關鍵畫面,搭配 Mobbin 把常見 flow 的關鍵狀態標成 3–5 類(例如:首頁、搜尋中、結帳中、錯誤頁)。技術上,不一定要 JEPA,一開始可以只是「畫面截圖 → 分類器」,把實際螢幕錄影自動對應到這幾個狀態。[8][2]
第 2 層:任務與意圖層(小型 LLM)
輸入:抽象狀態序列。
任務:判斷「使用者想幹嘛」、「任務有沒有成功」。
典型 owner:ML/資料科學
工具對照版:把這條「狀態序列」丟給你原本就用的 LLM(UXPilot、MagicPath 背後的模型),要它多做一件事:總結「這個 session 的任務是什麼、最後有沒有成功」。
第 3 層:對話與決策層(現有 LLM/代理)
輸入:意圖+任務狀態。
任務:決定要不要插手、給什麼建議、下一步開哪個畫面。
典型 owner:LLM 團隊+產品/設計
這種三層架構的重點是:讓決策者看到「我只要在現有 LLM 堆疊一層 UI-感知模組,就可以開始世界模型的過渡」,而不是被一堆 masking、embedding 嚇退。[10]
如果你只有一支小團隊,最務實的做法是:先讓「現有 LLM 小組」兼任第 2、3 層,把第 1 層外包為一個明確的 data/infra 專案,而不是全部同時自建。
案例處方:用兩個具體場景說「照著跑會發生什麼」
案例一:客服 App 的「不迷路導覽」
症狀描述(用 PM 的語言): 現在的智能客服可以回答所有 FAQ,但是:
用戶照著做,常常「走錯路」:按錯 tab、進錯設定頁。
LLM 完全看不到畫面,只能重複同一句話:「請到設定 → 通知」。
處方:加一層 UI-JEPA 式感知
現況
你用 Relume 生成客服網站的 sitemap 和 wireframe,再丟回 Figma 調整。[8]
你上 Mobbin 查「notification settings」的最佳實踐,照著別人的 flow 畫出「請到設定→通知」那幾步。[2]
你用 UXPilot / MagicPath 幫 chatbot 寫引導 script。
結果:用戶還是常常走錯 tab,bot 只能一遍遍重複同一句話。
多做的那半步
在 Relume / Figma sitemap 裡,選出 3–4 個關鍵畫面:
A:主畫面;B:設定但不在通知;C:通知設定;D:離開 App。
把真實客服 session 的螢幕錄影,交給一個簡單的「畫面 → A/B/C/D」分類器(可由外部 ML 夥伴實作)。
每當 chatbot 回覆時,多看一眼「目前狀態」。
如果連續 3 步都卡在 B,就自動切換成「一步一步帶你回主畫面」模式,而不是重複 FAQ 文案。
設計系統團隊的具體行動
把這個「客服不迷路」案例透過設計系統的眼光重新看,各個角色要做什麼?
UI Designer:在 Figma / Relume sitemap 裡,給「主畫面」「進入設定」「通知頁」明確的視覺標識,讓 AI 分類器即使拿到模糊或殘損的螢幕截圖,也能識別。
Interaction Designer:設計「AI 介入」的微互動:使用者走錯路時,不是突兀的 toast 通知,而是用動效引導回主路徑。
User Researcher:收集 100+ 真實客服 session 錄影,標註「使用者意圖」(例如:想關閉通知)與「失敗點」(例如:在 Wi-Fi 設定卡 3 分鐘)。這些資料是 UI-JEPA 的「世界觀訓練集」。
Prototype Designer:用 Figma prototype 模擬「有 AI 感知」vs「沒 AI 感知」的兩個版本,讓 PM 用定量指標來決定是否投資。
這樣你的設計系統就從「靜態元件」升級到了「可感知、可預測、可評估」的動態系統。
交付物與驗收標準:
1 份「任務狀態圖」+ 1 個簡單 UI-classifier 模型。
測試指標:
任務完成率提高 X%(例如:從 70% 提高到 85%)。
「走錯頁面超過 3 次才完成」的使用者比例下降 Y%(例如:從 20% 壓到 10% 以內)。
感覺是「一個季度內可以試水溫的專案」,而不是遙遠的世界模型願景。
風險與退出條件:如果三個月內,任務成功率改善 < 5% 或資料覆蓋率仍不足 30%,就暫停擴展,重新檢查資訊架構與流程設計,而不是繼續加模型。
案例二:醫療預約流程的「自動標記可用性問題」
症狀描述:
你知道預約流程很難用,但每次 usability test 成本高;
後台只有 event log,卻不知道「到底在哪個畫面大家放棄」。
處方:用 UI-JEPA 思路做「被動觀察」
現況
做醫療預約專案時,你會:
上 Mobbin 看「healthcare / booking」類 app,抄幾個不錯的 flow 當靈感。[2]
用 Relume / Figma 把預約流程畫成 sitemap 和高保真頁面。
做 5–10 場 usability test,再寫報告。
多做的那半步
把這些遠端測試的螢幕錄影和點擊紀錄整理出來。
依照你在 Mobbin 看到的標準作法,把流程切成 4–5 個節點:登入 → 選診所 → 選時段 → 填基本資料 → 確認 → 流失。
交給一個簡單的模型,「畫面 → 節點」,每天自動數:哪個節點掉人最多。
每週把這張「漏斗熱點圖」放進顧問報告,變成付費 deliverable。
交付物與驗收標準:
每週一份「預約漏斗熱點」報告(自動生成)。
驗收:3 個月內,最壞節點的中途放棄率下降 X%(例如:從 30% 降低到 15%)。
這種案例的重點不是技術細節,而是「有沒有把混亂轉成固定節奏的交付物」。
風險與退出條件:如果模型無法穩定把畫面分類到 3–5 個核心節點(準確率低於 80%),先回頭重構流程切點,而不是盲目增加網路深度。
設計團隊協作指南:拆解「UI 世界感知」的設計角色
當我們談論將「UI 世界感知」融入 AI 產品時,這不是單一設計師的任務,而是整個設計團隊的協作。這裡我為你拆解各個角色的具體職責和協作方式:
用戶研究員:
診斷:不再只是收集用戶的語言回饋,更要深入理解他們在介面中的實際行為模式,以及行為背後隱藏的意圖。
處方:與 介面設計師 緊密合作,共同定義核心用戶任務和關鍵路徑。利用螢幕錄影、眼動追蹤等工具,收集大量真實用戶互動數據,並協助標註這些數據中的「用戶意圖」和「狀態轉變」。他們的工作是為 UI-JEPA 提供高品質的「世界觀數據」。
交付物:詳細的用戶任務圖、關鍵意圖標註規範、可用性測試報告中新增的「意圖與狀態流失點」分析。
介面設計師 (UI Designer):
診斷:不只設計靜態美觀的畫面,更要設計出「AI 可理解」的介面元素和狀態。
處方:與 互動設計師 協作,將複雜的 UI 流程簡化為清晰、可識別的「狀態節點」。例如,一個購物流程可以被拆解為「瀏覽商品」、「加入購物車」、「結帳填寫」、「支付成功」等關鍵狀態。他們需要為每個狀態設計明確的視覺標識,確保即使是 AI 也能一眼「讀懂」畫面所處的階段。運用 Relume / Figma 等工具,產出帶有清晰狀態定義的 Sitemap 和 Wireframe。
交付物:帶有狀態註釋的 Sitemap、清晰的關鍵畫面設計、易於 AI 識別的元件規範。
互動設計師 (Interaction Designer):
診斷:不僅規劃用戶的點擊路徑,更要設計 AI 能「預測」和「引導」的互動流程。
處方:與 動效設計師 和 原型設計師 協作,為每個 UI 狀態轉變設計流暢且預期性高的互動。他們需要思考如何透過互動設計,讓用戶意圖更明確地被 AI 捕捉,同時在 AI 預測錯誤時,如何提供溫和、有效的引導機制。他們的工作就像是在為 AI 設計「腳本」,讓 AI 知道在不同「世界狀態」下該如何反應。運用 Mobbin 分析他人成功的互動模式,並在原型中融入「AI 可感知」的互動微調。
交付物:帶有 AI 感知點的互動流程圖、狀態轉換原型、用戶引導機制設計。
原型設計師 (Prototype Designer):
診斷:不只製作可點擊的原型,更要製作能「模擬 AI 感知」的互動體驗。
處方:與 互動設計師 協作,將介面設計師提供的靜態畫面和互動設計師提供的流程,組合成可測試的、包含「AI 反饋」的原型。例如,在原型中模擬當 AI 偵測到用戶「走錯路」時,會如何彈出提示或調整介面。他們需要確保原型能夠模擬出 AI 世界模型的感知層對用戶行為的反應,以便用戶研究員進行早期測試。
交付物:具備 AI 感知模擬的互動原型、用戶測試腳本中加入「AI 引導效果」的評估點。
動效設計師 (Motion Designer):
診斷:不只創造視覺上的流暢感,更要利用動效來「強化 AI 的意圖表達」與「用戶對 AI 狀態的理解」。
處方:與 互動設計師 協作,設計能清晰傳達 AI 預測、引導或反饋的微動效。例如,當 AI 成功預測用戶意圖並預先加載某些內容時,可以設計一個平滑的過渡動效。當 AI 提供引導時,動效可以幫助用戶更快地理解新的操作建議,減少認知負擔。他們的工作是讓 AI 的「智慧」在視覺上變得「有感」。
交付物:AI 反饋動效規範、狀態轉換動效設計。
透過這樣的協作模式,設計團隊不再只是獨立作業,而是形成一個緊密相連的迴圈,共同為 AI 產品建立一個「可感知、可預測、可引導」的 UI 世界。這不只是技術的進步,更是設計師思維的一場「心智革命」。
新思維:從「靜態元件庫」到「動態狀態系統」
傳統設計系統教我們:定義元件、風格、排版。但一旦 AI 開始參與介面決策,設計系統的邏輯需要進化。
根據最新的設計系統研究,所謂的「AI Experience Patterns」不再只是定義「UI 長什麼樣」,而是定義「UI 怎麼想」:
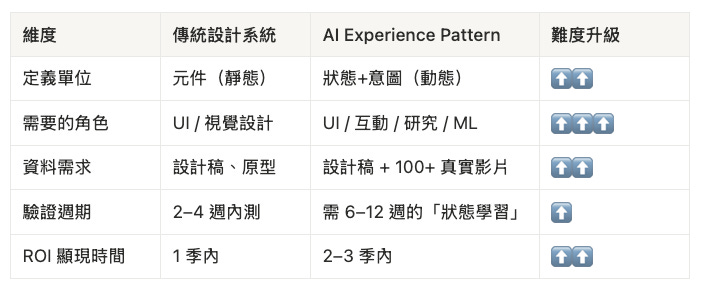
換句話說,你現在的 Figma 元件庫,需要多加三個層次的定義:
記憶 (Memory):系統記得什麼(單次 session、長期、集體)。
自主性 (Autonomy):系統有多少決策權(輔助、協作、完全自主)。
情境 (Context):系統怎麼理解情況(環境、情緒、操作)。
這不是學術名詞,而是說:你的設計系統從靜態的「長什麼樣」進化到動態的「怎麼想、怎麼看、怎麼反應」。
這正是世界模型思維要介入的地方。
隱藏的組織風險:誰來負責「螢幕狀態定義」?
這是最容易被忽略的一個坑。傳統 UX 團隊的職責清晰:UI Designer 負責視覺,Interaction Designer 負責流程,User Researcher 負責驗證。
但「AI 怎麼理解螢幕狀態」這件事,沒有人天生負責它。你需要明確指定:
誰來定義「什麼是狀態轉變」? → 通常是 Interaction Designer + User Researcher 的合作產物
誰來標註訓練資料? → 需要獨立的「Data Annotation 角色」,或委外
誰來驗收「AI 的理解」是否正確? → 需要 QA + UX 的協作
如果你現在的組織圖裡沒有上面這三個「責任交點」被明確畫出來,你的 UI-JEPA 試驗會變成「誰都可以做、誰都不負責」的爛尾專案。
成本啟示:如果要真正執行,你需要在現有 UX 團隊裡新增或重新分配 1–2 個「全職 FTE」來專門處理「狀態定義與標註」,這至少是額外的 10–15 萬美元 / 年(視地區和薪資)。
給設計師的警告:LLM 工具正在掩蓋一個根本問題
如果你最近一直在用 Figma AI、Relume、MagicPath 這類工具,你可能感覺效率大幅提升:60 秒生出一整個 sitemap、自動寫 copy、一鍵生圖。但這些工具的成功,其實掩蓋了一個更深層的問題。
根據 2025 年發表在 Elsevier 的系統文獻回顧,針對「LLM 在 UI/UX 設計中的應用」進行的 100+ 篇論文中,絕大多數都指向同一個問題:LLM 擅長「生成靜態畫面」,卻不擅長「理解動態流程」。
最常見的評論是:「當前的工具只能幫你搜出視覺上相似的設計,卻沒有捕捉應用的語義、使用者流程或螢幕在整個任務中的角色。」
設計師們在 Mobbin 上找靈感時,常常說:「我看到了很多 UI,但看不到它們在『使用者旅程』中的位置。」
這就是你為什麼開始心虛的原因。你用工具越來越快地產出設計,卻越來越不確定:AI 真的理解這些畫面所代表的「世界」嗎?
業界正在悄悄往這個方向走
你可能沒有注意,但 Apple、NVIDIA、Meta 等巨頭最近在大力投資的「物理 AI」與「World Foundation Models」,正在悄悄改變整個 AI 研發的方向。
V-JEPA 2(Meta 的最新世界模型)在 1.2 億參數的規模上,用 100 萬小時的影片訓練後,已經能預測機器人在陌生環境中的互動結果,準確率比傳統強化學習高出 40%。
更重要的是時間線:
2024 年上半年:Apple UI-JEPA 論文發佈,開始在 iOS 18 測試。
2025 年中期(現在):Meta V-JEPA 2 開源;Google 悄悄在 Android 助理中試驗狀態感知層。
預計 2026 年中期:主流廠商開始在商用產品中內建「螢幕狀態認知」作為標準配置。
換句話說,你現在的 18–24 個月窗口不是「未來可能」,而是「現在必做」。
三個「沒有退路」的起手式問題:現在就開始思考 AI 產品的未來
以下問題沒有「中立答案」。如果你無法清楚作答,代表你現在已經處於「盲人騎瞎馬」的狀態。
「我們今天如果要在 2 週內檢測:『客戶現在在應用的哪個步驟卡最久』,能做到嗎?」
如果能:你已有「狀態基礎」,可以直接進入 UI-classifier 試驗。
如果不能:你的「世界感知」完全缺失,現在只是在運氣上賭注。
「我們的 UX 團隊裡,有誰能解釋『為什麼這 5 個畫面可以讓 AI 準確分類出「使用者放棄了」』?」
如果有人能講清楚:你的設計系統已經開始向「AI 友善」進化。
如果沒有人能講:你的設計再美,AI 也看不懂。這跟蓋房子時沒人想過「機器人管家要怎麼在裡面活動」一樣。
「如果我們要透過 UI-JEPA 思路做一個試驗專案,我們有沒有『可以標註意圖』的真實使用者螢幕錄影?至少 50 個 session?」
如果有:可以立刻開始。
如果沒有:你需要先投資 6–8 週的「資料收集與標註流程」設計,才能開始試驗。這代表真實的前置成本。
快速自檢:你現在有多「心虛」?
勾選以下適用於你的情況:
☐ 我們的 AI 產品用了 LLM,但客服團隊經常反映:『它給的指引沒錯,但根本沒看清楚使用者現在在哪個畫面』
☐ 我們用 Figma / Relume 很快地做了 20+ 個頁面,但沒有人能清楚解釋『這些頁面之間,AI 怎麼區分彼此』
☐ 每次可用性測試,我們都發現 AI 的引導『技術上沒錯,但不符合脈絡』,解決方案就是『改 prompt』或『加更多例子』
☐ 我們完全沒有「螢幕狀態」或「UI 互動序列」的結構化資料。所有的使用者行為分析都只停留在事件 log 層次。
☐ 我們在 Mobbin 或其他設計庫裡看到最佳實踐,但無法自動檢測自己的產品是否達到那個標準。每次都是人工看,很耗時。
☐ 如果有人提到『把螢幕變成 AI 能預測的世界』,我們的團隊要嘛一臉茫然,要嘛立刻說『這太複雜了,超出預算』。
勾選結果
0–1 項:你走運,暫時還沒進入「盲點區」。但不要睡著,窗口在縮小。
2–3 項:你應該立刻組織一個「UI 感知層試驗」,時間不多了。
4–5 項:你現在的做法已經是技術債。不是「要不要改」,而是「什麼時候改」。
6 項全勾:坦誠地說,你的 AI 產品現在像是「有聲音但沒眼睛的人」。18 個月後,業界標配都是「有眼睛」的,你會被遠遠甩在後面。現在改革還不晚,但窗口真的在關。
引文來源:本摘要內容來自所提供的音頻轉錄文字。
參考文獻
Apple Machine Learning. (n.d.). UI Intent. Retrieved from https://machinelearning.apple.com/research/ui-intent
Aslan, E. (2024, August 29). Mobbin: The ultimate UI/UX design reference library for modern designers. Retrieved from https://eyuphanaslan.com/2024/08/29/mobbin-the-ultimate-ui-ux-design-reference-library-for-modern-designers/
BDTechTalks. (n.d.). UI-JEPA: Designed by Apple, inspired by Yann LeCun. Retrieved from

LeCun, Y. (n.d.). Yann LeCun. Wikipedia. Retrieved from https://en.wikipedia.org/wiki/Yann_LeCun
Marr, B. (2024, April 12). ‘Generative AI Sucks!’ Meta’s Chief AI Scientist Calls For A Shift To Objective-Driven AI. Forbes. Retrieved from https://bernardmarr.com/generative-ai-sucks-metas-chief-ai-scientist-calls-for-a-shift-to-objective-driven-ai/
Meta AI. (n.d.). Yann LeCun: The AI Model I JEPA. Retrieved from https://ai.meta.com/blog/yann-lecun-ai-model-i-jepa/
Quantum Zeitgeist. (n.d.). LeCun: Meta AI & AI Research. Retrieved from https://quantumzeitgeist.com/lecun-meta-ai-ai-research/
Relume. (n.d.). Relume. Retrieved from
https://www.relume.io
Towards AI. (n.d.). Inside World Models And V-JEPA: Building AI That Predicts Reality. Retrieved from https://pub.towardsai.net/inside-world-models-and-v-jepa-building-ai-that-predicts-reality-b24d3050be5c
UI-JEPA: Towards Active Perception of User Intent through Self-Supervised Learning from UI Interactions. (2024). arXiv. Retrieved from https://arxiv.org/abs/2409.04081
Copyright © PrivacyUX Consulting Ltd. All rights reserved.

Joshua 是 Agentic UX(代理式使用者體驗)的先驅,在人工智能與使用者體驗設計領域擁有超過 15 年的開創性實踐。他率先提出將用戶隱私保護視為 AI 產品設計的核心理念,於 2022 年創立 Privacyux Consulting Ltd. 並擔任首席顧問,積極推動隱私導向的醫療 AI 產品革新。此前,他亦擔任社交 AI 首席策略官(2022-2024),專注於設計注重隱私的情感識別系統及用戶數據自主權管理機制。