


[AI 創業] 命運硬幣,兩面極端:從台灣 Lawsnote 到美國 Anthropic,看懂扼殺與扶植創新的法律鴻溝
Code in the Crosshairs: Navigating the Legal Maze from Taiwan's Prison Sentence to Silicon Valley's Green Light.

一則判決,可以決定一個產業的生與死。

在台灣,一位律師背景的創業者,因為使用網路爬蟲抓取公開的法律資料,創辦了比官方更好用的法律搜尋引擎 Lawsnote,結果被判刑四年,賠償一億。
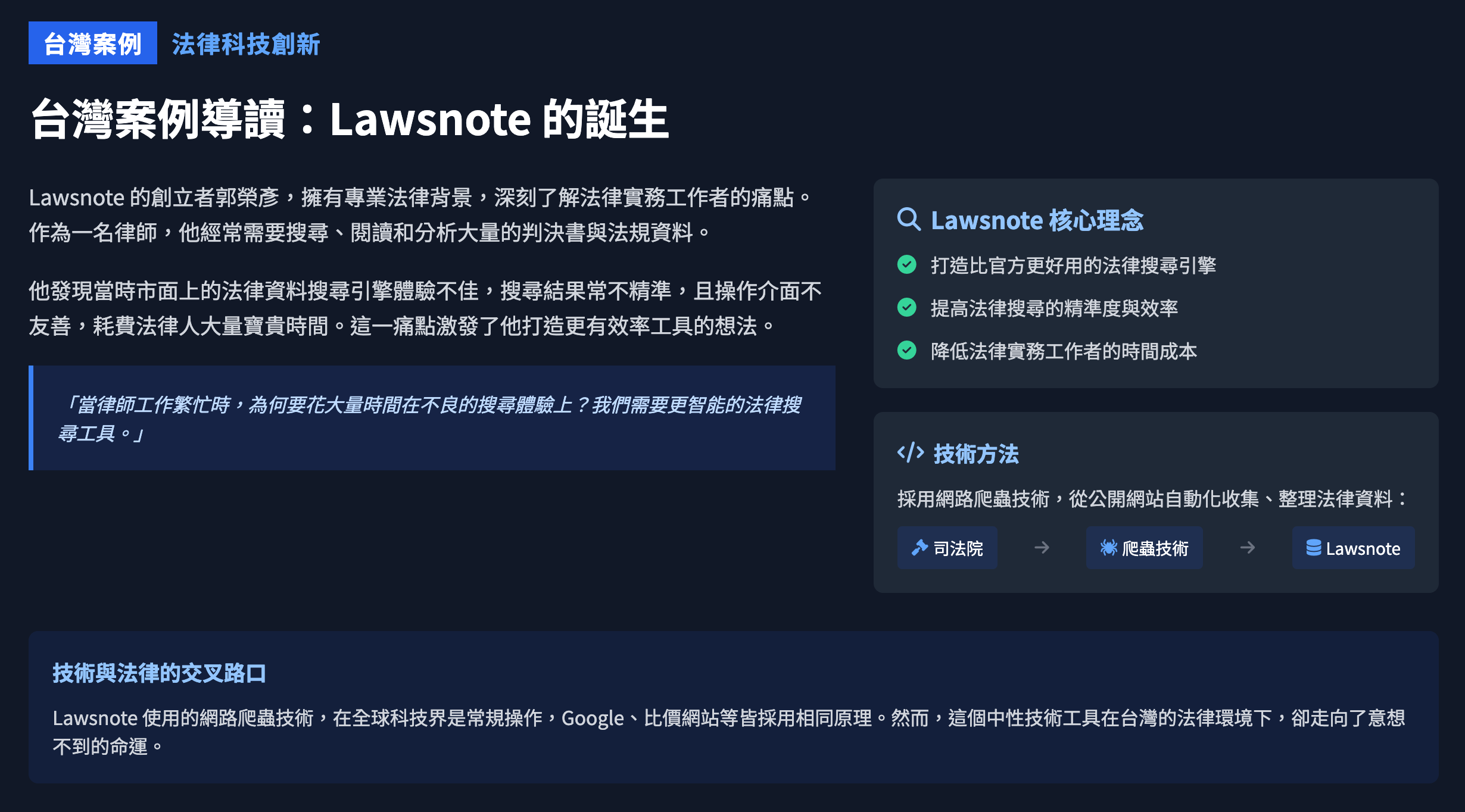
在美國,AI 巨頭 Anthropic 用合法購買的書籍訓練其大型語言模型 Claude,被作者控告,法院卻裁定這是「合理使用」,為 AI 創新開了綠燈。
一個是扼殺,一個是扶植。這兩個看似遙遠的案例,並列在一起時,揭示了台灣與美國在面對新科技時,法律思維上的巨大鴻溝。這道鴻溝,不僅僅是法條的解讀差異,更直接決定了創業者是走向領獎台,還是走向監獄。
台灣的「紅燈」:為何抓取「公開資料」會成為重罪?
新北地方法院的判決,給了這個充滿理想主義的創業故事一個毀滅性的結局。法院的判決邏輯,主要基於兩點,而這兩點都充滿了巨大的爭議:
1. 妨礙電腦使用罪:複製貼上 vs. 駭客入侵

如果 Lawsnote 的行為有罪,那是否意味著未來所有在台灣的爬蟲應用——包含學術研究、商業分析、新聞聚合——都籠罩在刑事責任的陰影下?甚至,我們手動從網頁上複製一段文字,是否也可能落入「無故取得他人電磁紀錄」的範疇?
這個判決,等於是將一個中性的技術工具,直接打上了「犯罪工具」的標籤,這對所有仰賴資料驅動創新的台灣新創,無疑是釜底抽薪。
2. 著作權的無限上綱:公開資料 vs. 編輯著作

Lawsnote 案的判決,幾乎是以最嚴苛、最不利於創新的方式,去解讀法律。它傳達了一個清楚的訊息:在台灣,只要你動了別人的「公開」資料,即便你是為了創造更大的價值,你都可能成為罪犯。

美國的「綠燈」:為何訓練 AI 是「轉化性使用」?
將場景切換到美國,我們看到了截然不同的風景。

這看起來是個比 Lawsnote 案更明確的「侵權」行為——Anthropic 和 Meta 使用的不是「公開資訊」,而是受版權保護的「書籍內容」。

然而,美國聯邦法院的判決,卻走向了完全相反的方向。不論是 Anthropic 案還是 Meta 案,法官的核心見解都圍繞著「轉化性使用」(Transformative Use)。法官認為,雖然 AI 公司使用了版權作品,但其目的是為了訓練一個 AI 模型,而非複製或取代原作來銷售。AI 模型的產出是一個全新的、不同的東西,這個過程本身就具備高度的「轉化性」。

從 Google Books 到 GitHub Copilot,再到這次的 Anthropic 與 Meta 案,我們看到美國司法系統在「技術創新」與「版權保護」的拉鋸中,始終為前者保留了一條通路。他們保護的不是複製的行為本身,而是創新的結果與目的。

然而,這種台美對比只是冰山一角。事實上,在全球範圍內,即使沒有專門的 AI 法規,各國法院也早已被推上第一線,成為 AI 技術的「事實監管者」(de facto regulators)。一篇分析了 39 個國家、超過 500 起 AI 相關訴訟的研究報告《AI on Trial》揭示,法院正在透過個案判決,為新興科技劃定法律邊界。其中三大領域的案件,就佔了近四成 。
這些來自不同國家的真實案例說明,AI 的法律挑戰遠不止於版權。單純將爬蟲視為犯罪,或將 AI 訓練完全歸為合理使用,都過於簡化。現實世界中,風險的高低取決於更細緻的技術與應用情境:
爬蟲的合法性光譜:爬蟲本身是中性工具,其合法性取決於多重因素:抓取的是否為需要登入的私密資料?是否違反網站明確的服務條款(ToS)?抓取的頻率是否高到影響對方伺服器運作?用途是商業還是學術?在歐盟,由於嚴格的 GDPR,即便抓取公開的個人資料,也需要有明確的法律基礎。將所有爬蟲行為都視為妨礙電腦使用,是對技術的誤解。
AI 訓練的風險遞增:並非所有 AI 訓練都一樣。「合理使用」的空間大小,與其對原作品市場的潛在威脅成反比。風險由低至高可大致分為:
預訓練 (Pre-training):風險最低。此階段使用來自網路的通用、大規模、多樣化的資料集,任何單一作品的佔比都極低,模型學到的是廣泛的語言規律而非特定內容,生成結果高度抽象,幾乎不構成市場替代。
微調 (Fine-tuning):風險提高。此階段使用更小、更專業的資料集來優化模型在特定領域的能力。由於資料集更集中,單一作品的影響力變大,模型更有可能生成與原作風格或表達方式相似的內容。
檢索增強生成 (RAG, Retrieval-Augmented Generation):風險最高。RAG 系統在生成答案時,會直接從外部的特定資料庫中檢索資訊。其輸出與被檢索的資料高度相關,若該資料庫受版權保護,其生成結果就極可能直接替代原作品的市場功能,構成侵權的可能性也最大。
台灣的判決,傳遞的訊息是:不要碰數據,除非你獲得了所有權利人的明確授權,即使那是公開數據。 這等於直接判了數據驅動型新創的死刑。
美國的判決,傳遞的訊息是:去創新吧,只要你的用途是轉化性的,並且沒有摧毀原作的市場,法律會保護你。
給 AI 創業家的啟示:從「法律風險」到「信任資產」的策略佈局
這兩個案例,對所有從亞洲出發、放眼全球市場的 AI 創業者,提供了從生存到成功的清晰路徑。法律不該只是風險,更可以透過策略性佈局,轉化為贏得信任的資產。

第一步:活下去 —— 選擇你的「司法安全區」
這是 Lawsnote 案最血淋淋的教訓。在啟動專案前,創辦人最重要的工作,就是找到一個對創新友善的「司法安全區」(Legal Safe Zone)。你必須自問:我的公司註冊在哪裡?我的核心業務(例如資料抓取、模型訓練)在這個國家是否受到像美國「合理使用」原則一樣的保護?
這個選擇,決定了你的創新是走在合法的陽光下,還是隨時可能被判入獄的鋼索上。在 AI 時代,選擇對的司法管轄區,其重要性不亞於選擇對的技術架構。
第二步:走出去 —— 取得全球市場的「法律通行證 (GDPR)」
確保了基本的生存權後,下一步就是走向世界。如果你的目標市場包含歐洲,那麼理解 GDPR 就不是一個選項,而是一張強制性的「法律通行證」。
GDPR (通用資料保護規則) 不是一個「認證」,而是歐盟的法律。只要你處理任何歐盟居民的個人資料,就必須遵守。它的核心是賦予用戶對其資料的控制權。對創業者來說,遵循 GDPR 意味著:
市場准入:合法進入擁有數億高價值用戶的歐洲市場。
風險規避:避免高達全球年營業額 4% 的毀滅性罰款。
這不是法務部門的事,而是商業戰略的核心一環,它強迫你從第一天起就以最高標準來設計你的數據處理流程。
第三步:贏得信任 —— 打造 B2B 業務的「信任徽章 (SOC 2)」
當你合法地進入市場後,如何贏得客戶,尤其是高價值 B2B 客戶的信任?答案可能就是 SOC 2。
SOC 2 (系統與組織控制報告) 是一個源自美國的自願性稽核框架。它不像 GDPR 那樣是強制法律,而更像是一枚向客戶展示你安全可靠的「信任徽章」。當你要將服務賣給對資安有嚴格要求的企業時,一份 SOC 2 報告能極大地加速銷售流程,因為它證明了你的系統在安全性、可用性、隱私性等方面,都通過了獨立第三方的嚴格檢驗。
第四步:向前看 —— 參與並利用在地的政策改革
除了用腳投票,更積極的策略是向前看,參與並利用正在發生的政策轉變。以台灣為例,儘管 Lawsnote 案令人沮喪,但改變的訊號也已出現。
為了解決繁體中文 AI 訓練資料的困境,台灣數位發展部已啟動「台灣主權 AI 訓練語料庫」的建置計畫,目標是透過政府帶頭,以自願授權或使用無版權資料的方式,建立一個可供國內外模型免費使用的「乾淨」資料池。
這對創業者意味著,未來將有機會在台灣本地,以更低的法律風險和成本,取得高品質的訓練資料。關注並參與這類計畫,不僅能幫助自身業務,也能共同形塑一個對創新更友善的環境。
結論:你的選擇,決定你的未來

Lawsnote 和 Anthropic 的故事,以及 GDPR 和 SOC 2 的存在,共同描繪了當代 AI 創業的真實地圖。
它告訴我們,創新不僅僅是技術和商業模式的競賽,更是法律框架、全球視野和信任策略的競賽。一個國家選擇擁抱怎樣的法律精神,就等於選擇了怎樣的科技未來。台灣的制度困境在於,著作權法對合理使用的定義狹隘,缺乏「轉化性」概念,且對文字與資料探勘(TDM)無明確規範,導致法院傾向以過時的出版思維來審視新科技。
然而,改變的契機正在浮現。不論是借鑒歐盟、日本增訂 TDM 例外條款,或是建立公益資料池,都是台灣可以走的路。
而對於創業者,你能做的最重要的事情,就是在充分理解全球法律地貌的前提下,做出最有利的策略選擇。去那個能讓你安心創造、合法擴張、並能有效建立信任的地方。因為在那裡,你的程式碼,才更有可能改變世界,而不是變成呈堂證供。
如果台灣繼續以 20 世紀的出版思維治理 AI 專案,那我們將只能在國際科技浪潮中扮演觀眾,而非參與者。
參考資料
[1] Isadora Valadares Assunção, "Beyond Regulation: What 500 Cases Reveal About the Future of AI in the Courts," Tech Policy Press, May 20, 2025. https://techpolicy.press/beyond-regulation-what-500-cases-reveal-about-the-future-of-ai-in-the-courts
copyright © PrivacyUX consulting ltd. All right reserved.
關於本刊作者
Gainshin Hsiao 是 Agentic UX(代理式使用者體驗)的先驅,在人工智能與使用者體驗設計領域擁有超過 15 年的開創性實踐。他率先提出將用戶隱私保護視為 AI 產品設計的核心理念,於 2022 年創立 Privacyux Consulting Ltd. 並擔任首席顧問,積極推動隱私導向的醫療 AI 產品革新。此前,他亦擔任社交 AI 首席策略官(2022-2024),專注於設計注重隱私的情感識別系統及用戶數據自主權管理機制。
Agentic UX 理論建構與實踐
AI 隱私保護設計準則
負責任 AI 體驗設計
在 Cyphant Group 設計研究院負責人任內(2021-2023),他探索了 AI 系統隱私保護準則,為行業標準做出貢獻。更早於 2015 至 2018 年,帶領阿里巴巴集團數位營銷平台體驗設計團隊(杭州、北京、上海、廣州)、淘寶用戶研究中心並創立設計大學,從零開始負責大學的運營與發展,不僅規劃了全面的課程體系,更確立了創新設計教育理念,旨在為阿里巴巴集團培育具備前瞻視野與實戰能力的設計人才。其課程體系涵蓋使用者中心設計、使用者體驗研究、數據驅動設計、生成設計等多個面向應用。
活躍於國際設計社群,在全球分享 Agentic UX 和 AI 隱私保護的創新理念。他的工作為建立更負責任的 AI 生態系統提供了重要的理論基礎和實踐指導。
學術背景
Mcgill - Infomation study/HCI -Agentic UX, Canada
Aalto Executive MBA-策略品牌與服務設計, Singapore
台灣科技大學:資訊設計碩士- HCI, Taiwan
中原大學:商業設計學士- Media and marketing design, Taiwan