


破解AI的隱形缺陷:為何第三方視角不可或缺
AI's Flaws, Deep and Unseen, A Third-Party View, Sharp and Keen, The Crucial Mean.


信任危機的暗湧:系統缺陷與回報困境
當一名醫生使用AI輔助診斷系統,卻發現其在非白人患者的皮膚病變識別上存在明顯偏差;當一位記者測試專屬AI助理,卻發現它提供的「歷史事實」完全是幻覺編造——這些問題的發現者往往面臨一個共同困境:缺乏有效的回報渠道。在目前的AI生態系統中,當用戶或公眾發現人工智能的缺陷,常常陷入進退兩難的處境:要麼將發現石沉大海,要麼被迫訴諸社交媒體的公開批評。這種回報機制的缺失正在侵蝕對AI系統乃至整個AI產業的信任基礎。
與此同時,AI產業盛行「敏捷開發」理念,強調快速迭代和「先發布再完善」。這種開發模式在傳統軟體領域或許行之有效,但在AI領域卻面臨獨特挑戰。AI系統的缺陷影響往往比傳統軟體更加深遠且難以預測,一個看似微小的偏見或推理錯誤可能隨著系統的大規模部署而被放大成系統性風險。當這種快速迭代模式缺乏配套的外部監測與響應機制時,我們很容易將未成熟、潛在風險未被充分評估的AI產品推向市場,最終可能損害用戶權益並引發公共信任危機。
失落的回饋環:AI領域的結構性不足
當前AI系統的缺陷多種多樣,從所謂的「幻覺」(生成虛假但看似可信的信息)到資料偏誤(在特定人群或情境下表現不一),再到各種訓練產生的盲點。值得注意的是,這些問題往往在模型從實驗室進入現實世界後才逐漸顯現。相較於網路安全和傳統軟體開發等成熟領域,AI產業在缺陷回報與修復機制上顯得尤為落後。
現實情況是,大多數AI開發公司主要依賴內部測試團隊或少數特約承包商來發現問題。這種封閉式的質量保證模式在面對現實世界無限多樣性的應用場景和用戶需求時,顯得力不從心。一個內部團隊無論多麼優秀,都無法預見所有可能的失敗模式,特別是那些只有在特定文化、社會或專業背景下才會出現的問題。
在網路安全領域,「白帽駭客」文化早已成為行業標準——鼓勵外部專家在嚴格的道德和法律框架下,主動尋找並回報系統漏洞。這種模式不僅催生了「抓蟲獎勵」(bug bounties)等激勵機制,更形成了一個健康的安全生態系統,顯著提升了產品的安全性。然而,AI領域尚未發展出類似的協作文化。
AI的缺陷與傳統軟體的bug或資安漏洞有著本質區別,它可能涉及更加微妙的問題,如語言理解的偏見、邏輯推理的盲點,甚至特定群體中的歧視性結果。這些問題的識別往往需要多元背景的使用者參與,而非僅靠開發團隊內部視角。中立的第三方用戶——醫生、法律專家、教育工作者、不同文化背景的普通使用者——恰恰是發現這些「看不見的角落」的理想人選。
借鏡資安模式:構建AI缺陷回報的三大支柱
針對上述問題,史丹佛大學的研究團隊提出了一套完整的AI缺陷回報框架,旨在打破當前的閉環困境。這個框架由三大核心支柱構成,每一個都針對目前生態系統中的特定缺口。
1. 標準化回報範本:共同語言的力量
第一個支柱是建立一套標準化的AI缺陷回報範本。這不僅是一個技術文檔,更是一套行為準則和交流協議。這一範本受到網路安全領域「負責任揭露」(responsible disclosure)原則的啟發,明確規定了回報者需遵循的基本原則:不傷害用戶、保護隱私、以建設性方式溝通問題。
標準化範本的關鍵價值在於提高缺陷的可再現性和可理解性。它要求回報者提供足夠詳細的信息,包括問題的具體表現、觸發條件、潛在影響以及可能的再現步驟。這些結構化信息能夠幫助開發者快速理解問題本質,評估其嚴重程度,並分類處理。更重要的是,標準化範本建立了開發者與回報者之間的共同語言,促進了有效溝通,避免了信息不對稱造成的誤解和摩擦。
2. 法律「安全港」:打破回報障礙
許多AI公司出於保護知識產權和商業利益的考慮,透過使用條款和法律手段限制外部人士對其模型進行探索、逆向工程或系統性測試。這種保護主義傾向雖然可以理解,但卻成為識別潛在風險的重大障礙。當善意的研究者和用戶害怕因發現並報告問題而面臨法律訴訟或帳戶封禁時,許多重要缺陷就可能被掩蓋,直到造成實質性損害。
框架的第二個支柱因此呼籲建立法律和技術上的「安全港」(safe harbor),為善意的AI系統評估者提供保護。這種保護機制在網路安全等高風險領域已經證明有效,如美國《數位千禧年著作權法》(DMCA)中的安全港條款,以及各大科技公司紛紛採用的漏洞回報政策。這些政策明確表示,在遵循特定準則的前提下,公司不會對發現並負責任回報漏洞的研究者提起法律訴訟。
為AI領域建立類似的法律保護機制,不僅能鼓勵更多善意的缺陷回報,還能提升整個產業的安全標準和用戶信任。開發公司可能擔心開放測試會導致商業秘密洩露或惡意利用,但精心設計的安全港框架可以在鼓勵報告的同時,對測試範圍和方法設定合理限制,實現雙贏。
3. 缺陷揭露協調中心:共享智慧的平台
框架的第三個支柱是建立「缺陷揭露協調中心」(Disclosure Coordination Center),作為AI缺陷信息的中央交換平台。這一創新概念源於一個重要觀察:AI的缺陷往往具有「可轉移性」,即在一個系統中發現的問題,很可能同時存在於使用相似資料、架構或方法訓練的其他系統中。
這個協調中心將記錄已知的AI缺陷以及開發者處理這些缺陷的進展,創建一個公開、透明的問責機制。它不僅能促進開發者之間的知識共享,幫助他們從彼此的經驗中學習,還能為用戶提供重要的風險評估参考。協調中心的存在將標準化和簡化整個AI產業的溝通流程,大幅提升缺陷識別和修復的效率。
此外,協調中心還能作為研究和政策制定的資料庫,幫助識別AI系統中的共同弱點和系統性風險。這些聚合數據對於制定更有針對性的行業標準和監管框架具有重要價值,最終提升整個AI生態系統的安全性和可靠性。
Agentic UX與缺陷回報:代理式互動的新視角
代理互通性與缺陷發現
在討論AI缺陷回報機制時,我們不能忽視一個正在興起的關鍵概念:代理式使用者體驗(Agentic UX)。這種新型體驗模式徹底改變了人與AI的互動方式:使用者不再與介面直接互動,而是與AI代理人交流需求,由代理人協調執行任務。在此模式下,缺陷回報機制面臨著全新的挑戰和機遇。
首要挑戰是互通性(interoperability)。正如研究文獻所指出,不同框架、不同供應商開發的AI代理人無法有效溝通,形成「智慧孤島」。這種孤立性不僅影響使用者體驗的連貫性,也嚴重阻礙了缺陷的發現和回報。當一個代理系統出現問題時,若缺乏與其他代理的有效溝通渠道,這些問題可能無法被及時識別和共享,導致同類錯誤在多個系統中反覆出現。
為解決這一挑戰,業界正在發展兩種互補的協議標準:Google的Agent2Agent(A2A)協議專注於AI代理之間的通訊,而Anthropic的Model Context Protocol(MCP)則聚焦於AI模型與外部工具的連接。在缺陷回報情境中,這些協議可以發揮關鍵作用:A2A協議可以實現不同AI系統間的缺陷自動通報,當一個系統識別到特定類型的問題時,能夠主動通知可能受到類似影響的其他系統;MCP則可以提供AI代理與缺陷回報工具之間的標準化接口,簡化回報流程,提高資訊的準確度和完整性。
多代理協作的監督與修復機制
多代理協作在缺陷識別與修復中具有巨大潛力。傳統的缺陷回報往往依賴單一渠道,效率低下且視角有限。而在代理式體驗框架下,我們可以構建由多個專業AI代理組成的監督網絡,各司其職、互相配合:
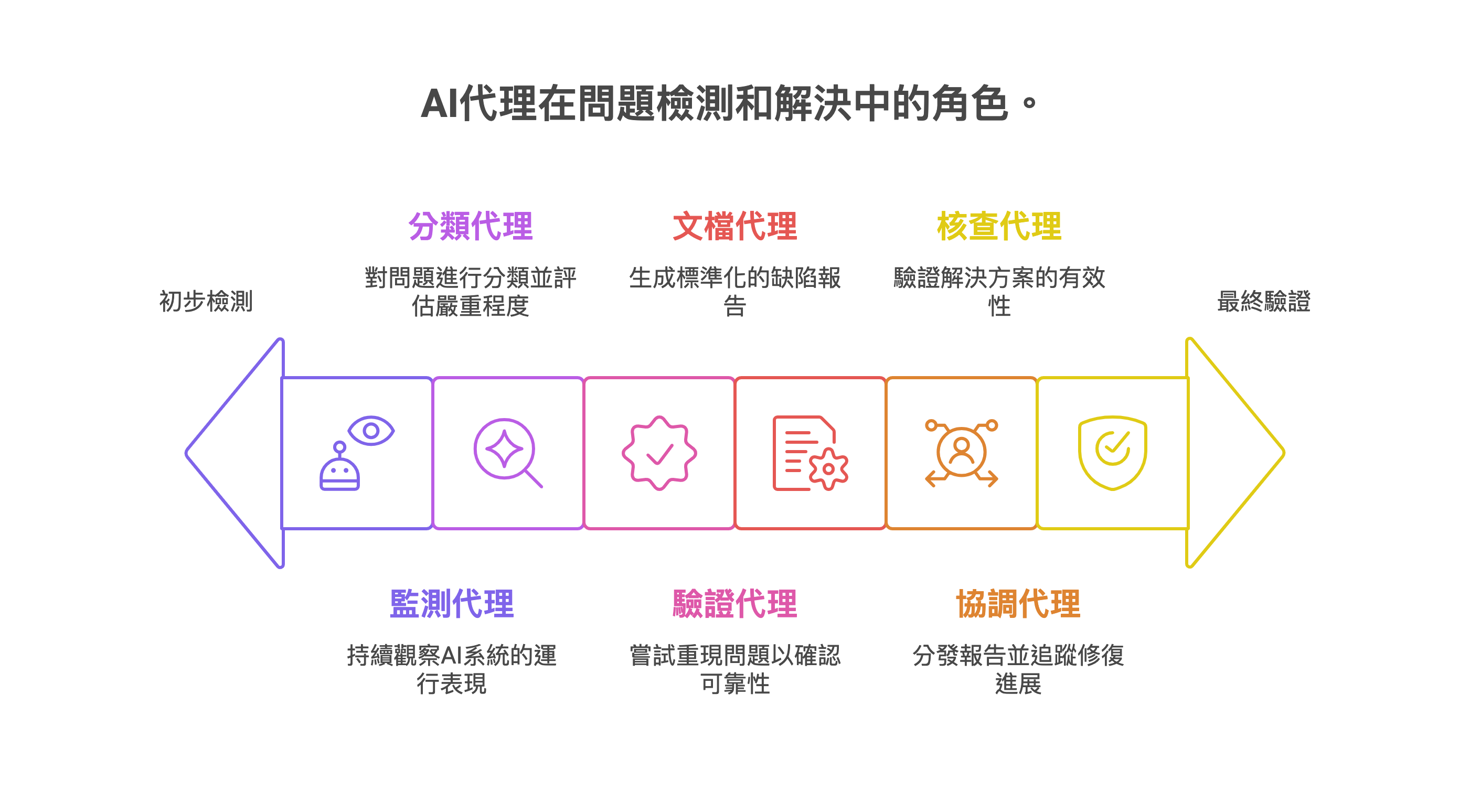
這種多代理協作模式能夠大幅提升缺陷管理流程的效率和透明度。使用者不必了解複雜的報告格式或技術細節,只需向主代理表達他們觀察到的問題,後續的分析、驗證和追蹤工作就會由代理網絡自動完成。同時,開發者也能獲得更加結構化、詳細的缺陷報告,加速修復流程。
透明度與控制權平衡
然而,在擁抱代理式缺陷回報的同時,我們必須關注透明度與控制權的平衡。如前所述,「使用者控制優先」是Agentic UX的核心原則之一,這在缺陷回報機制中尤為重要。系統必須清晰地向使用者展示:
哪些信息將被收集和分析
這些信息將如何被使用及分享
使用者在過程中擁有哪些控制選項
如何查詢缺陷修復的進展
同時,系統應遵循「錯誤恢復的優雅設計」原則,提供清晰的錯誤提示和後備方案,確保即使在代理系統本身出現問題時,使用者仍能通過傳統渠道報告缺陷。
透明度還應延伸至缺陷處理的全過程。「透明的代理協作」原則要求系統向使用者和開發者展示各代理在缺陷處理流程中的角色和活動,建立對代理決策的可問責性,增強整個生態系統的信任基礎。
從視野盲點到全景視角:整合多元洞見
回顧其他研究中的相關見解,我們可以從更廣闊的視角理解AI缺陷回報機制的重要性及其挑戰。
首先,AI系統的「黑箱」特性是一個根本性障礙。當系統的決策過程對用戶而言完全不透明時,即使專業人士也難以判斷結果是否合理,更遑論識別和精確描述潛在缺陷。缺陷回報機制必須思考如何在保護商業機密的同時,提供足夠的透明度讓外部評估者能夠理解並回報問題。這種平衡至關重要,也極具挑戰性。
其次,AI缺陷的發現高度依賴多元視角。單一文化或背景的開發團隊往往存在共同的盲點,而這些盲點只有通過接觸不同生活經驗的用戶才能被發現。例如,一個影像識別系統在某個特定民族的臉部識別上的失敗,往往只有該民族的用戶才能有效發現。因此,缺陷回報機制不僅需要技術上的完善,還需要社會包容性的設計,降低參與門檻,鼓勵和重視來自多元背景用戶的反饋。
第三,我們需要認識到部分AI缺陷源於更深層次的理解能力缺失。正如Yann LeCun所指出的,當前的大型語言模型「對物理世界的理解甚至不如一隻家貓」。這意味著某些「缺陷」實際上反映了模型的根本局限,而非簡單的技術bug。缺陷回報系統需要能夠區分「可修復的具體缺陷」與「模型本質局限所致的問題」,並相應地引導不同的解決方案或期望管理。
自監督學習(SSL)與用戶反饋的整合提供了另一個重要視角。一個設計良好的缺陷回報系統不僅是修復已知問題的工具,更可以成為AI系統自我進化的數據源。用戶回報的案例可以被轉化為寶貴的訓練數據,持續優化模型性能。這種「人機協同進化」的良性循環,是AI系統長期健康發展的重要保障。
最後,從倫理責任的角度看,AI缺陷回報機制體現了開發者對用戶的尊重和對技術本身的謙卑。技術應始終為人類服務,而透明、開放的缺陷回報渠道是實現這一價值觀的具體體現。特別是在AI缺陷可能導致實質傷害的場景中,建立有效的回報和修復機制不僅是技術問題,更是開發者的倫理責任。
Agentic RAG與缺陷探測的自主化
在AI缺陷回報的未來發展中,Agentic RAG(檢索增強生成)技術展現出獨特的潛力。傳統的RAG系統依賴靜態方法,從向量數據庫檢索知識並輸入LLM進行綜合。而 Agentic RAG引入自主檢索代理,基於迭代推理主動改進其搜索,更有效地探索和識別潛在問題。
在缺陷回報情境中,Agentic RAG可以實現更主動、更全面的問題探測:當用戶報告一個可能的缺陷時,系統不僅能理解當前問題,還能主動搜尋相關情境、類似案例和潛在影響,形成更全面的缺陷認知。這種方法特別適合處理複雜、多維度的缺陷,例如那些只在特定條件組合下出現的問題。
技術的發展還使我們能夠構建更完善的多代理評估系統。如研究文獻所指出,多代理系統的評估可以引入新的衡量指標,如對話效率、任務完成度和協作涌現,專門量化「AI團隊合作能力」。在缺陷回報領域,這些指標可以幫助我們評估代理系統發現、分析和修復缺陷的整體效能,不僅關注個別代理的表現,更關注整個協作網絡的協同效果。
從理論到實踐:邁向更安全的AI生態系統
目前,AI缺陷回報的現狀仍不理想:善意的發現者要麼是寄出電子郵件後石沉大海,要麼被迫在社交媒體上公開批評以引起關注。這兩種方式都無法形成系統性的解決方案,甚至可能加劇開發者與用戶之間的對立情緒。
令人鼓舞的是,史丹佛大學的研究團隊已經開始將理論框架轉化為具體行動。他們正在建立一個提交標準化缺陷報告的網站原型,並與產業合作夥伴洽談試行「缺陷揭露協調中心」的概念。這些努力雖然還處於起步階段,但已展現出深厚的實踐潛力。
成功實施這一框架需要多方參與:AI開發公司需要改變現有政策,開放更多測試和回報渠道;研究人員和用戶需要主動參與缺陷識別並使用標準化工具進行回報;政策制定者需要考慮如何在法律層面為善意的缺陷回報提供保護;行業組織則需要投資共享的基礎設施和標準,促進全行業的協作。
同時,隨著 Agentic UX理念的普及,我們還需要考慮不同企業規模的實施策略:小型企業可採用「最小可行的代理式體驗」,專注於核心功能的代理化;中型企業適合MCP與A2A並行的混合策略,在內部優先採用MCP,在跨部門協作中實驗A2A;大型企業則應建立全面的代理治理框架,整合兩種協議,並設立專門的代理策略辦公室協調各部門的代理開發。
無論企業規模如何,都應遵循共同的設計原則:使用者控制優先、漸進式揭露代理能力、錯誤恢復的優雅設計、意圖與行動分離,以及透明的代理協作。這些原則確保代理系統既能高效完成任務,又能保持使用者的信任和控制感。
雖然挑戰重重,但建立健全的AI缺陷回報生態系統是值得的。這不僅關乎技術進步,更關乎公共信任的建立和維護。隨著AI系統日益深入人類社會的各個領域,從醫療診斷到司法決策,從金融評估到教育選拔,確保這些系統的可靠性和安全性已成為不可回避的責任。
黑箱設計與使用者信任危機
從「黑箱設計與失落的使用者信任」的觀點來看,許多AI系統的決策過程對用戶而言如同不透明的「黑箱」。這種不透明性不僅阻礙了外部人士發現和回報缺陷,更深刻影響了用戶對AI的信任度。當用戶無法理解AI如何做出決策,也就無法有效判斷和回報其潛在的缺陷或偏見。缺陷回報機制必須考慮如何在保護商業機密的同時,提供足夠的透明度讓外部評估者能夠理解並回報問題。
多元視角與包容性設計缺失
從「設計偏見與多元視角」相關的討論中可見,單一文化或背景的開發團隊往往會產生偏見盲點。AI系統的許多缺陷源於訓練數據和設計過程中的偏見,而這些偏見往往需要多元背景的用戶才能發現。現有的AI缺陷回報機制若僅限於特定群體(如技術專家)使用,將難以發現影響少數群體或特定文化情境下的問題。因此,缺陷回報機制應當降低技術門檻,鼓勵多元背景的用戶參與回報。
AI的根本局限與「世界模型」缺失
參考Yann LeCun 的觀點,當前的大型語言模型「對物理世界的理解甚至不如一隻家貓」。這種根本局限意味著許多AI缺陷不僅是表面的「bug」,而是更深層次的理解能力缺失。單純的缺陷回報與修復機制可能無法解決這種本質局限,需要與更深層次的AI研發方向相結合,比如發展多模態學習能力和建立更完善的「世界模型」。缺陷回報系統應當能夠區分「可修復的具體缺陷」與「模型本質局限所致的問題」,並相應地引導不同的解決方案。
自監督學習與用戶反饋的整合
LeCun強調自監督學習(SSL)在AI發展中的核心地位,這與用戶回報缺陷的機制形成互補。一個設計良好的缺陷回報系統,不僅能作為修復已知問題的渠道,還可以為AI系統提供寶貴的自我完善數據。例如,用戶回報的幻覺案例可以被整合到後續模型訓練中,增強模型對自身不確定性的識別能力。未來的缺陷回報機制可能需要更緊密地與模型的持續學習系統整合,形成「人機協同進化」的良性循環。
技術與倫理責任的平衡
技術開發者需要在創新與責任之間取得平衡。AI缺陷回報機制不僅是技術問題,更是倫理責任的體現。正如文中所言「技術應該為人類服務,而非相反」,回報機制的設計應考慮如何保護人類權益,特別是在AI缺陷可能導致實質傷害的場景中。同時,缺陷回報機制的透明與公開也體現了科技公司對用戶的尊重,打破了「設計者與用戶間的權力差距」,最終促進更健康的技術生態系統。
copyright © PrivacyUX consulting ltd. All right reserved.
關於本刊作者
Gainshin Hsiao 是 Agentic UX(代理式使用者體驗)的先驅,在人工智能與使用者體驗設計領域擁有超過 15 年的開創性實踐。他率先提出將用戶隱私保護視為 AI 產品設計的核心理念,於 2022 年創立 Privacyux Consulting Ltd. 並擔任首席顧問,積極推動隱私導向的醫療 AI 產品革新。此前,他亦擔任社交 AI 首席策略官(2022-2024),專注於設計注重隱私的情感識別系統及用戶數據自主權管理機制。
Agentic UX 理論建構與實踐
AI 隱私保護設計準則
負責任 AI 體驗設計
在 Cyphant Group 設計研究院負責人任內(2021-2023),他探索了 AI 系統隱私保護準則,為行業標準做出貢獻。更早於 2015 至 2018 年,帶領阿里巴巴集團數位營銷平台體驗設計團隊(杭州、北京、上海、廣州)、淘寶用戶研究中心並創立設計大學,從零開始負責大學的運營與發展,不僅規劃了全面的課程體系,更確立了創新設計教育理念,旨在為阿里巴巴集團培育具備前瞻視野與實戰能力的設計人才。其課程體系涵蓋使用者中心設計、使用者體驗研究、數據驅動設計、生成設計等多個面向應用。
活躍於國際設計社群,在全球分享 Agentic UX 和 AI 隱私保護的創新理念。他的工作為建立更負責任的 AI 生態系統提供了重要的理論基礎和實踐指導。
學術背景
Mcgill - Infomation study/HCI -Agentic UX, Canada
Aalto Executive MBA-策略品牌與服務設計, Singapore
台灣科技大學:資訊設計碩士- HCI, Taiwan
中原大學:商業設計學士- Media and marketing design, Taiwan