
[AI 專業好書陪讀] 第4章:數位雙胞胎 - 系統物理組件的數位表示
Digital Twin—Digital Representation of the Physical Components of Your System

章節概述:一個慘痛的教訓與一個成功的典範
數位雙胞胎(Digital Twin)是實體世界的虛擬模型,專門用來分析該系統中最重要的衡量指標與成果。對於 AI 產品的用戶體驗(UX)設計而言,這是一個極佳的建模工具,它恰好座落在 UX for AI 設計能有效展現其巨大潛力的交會點上。
成功的典範:簡潔有效的風機馬達
與之形成鮮明對比的是奇異(GE)公司為其離岸風力發電機設計的數位雙胞胎。他們並未試圖監控整台複雜的風機,而是聚焦在一個相對簡單卻關鍵的組件上:偏航馬達 (yaw motor)。
這個數位雙胞胎模型極其簡潔:
輸入: 只收集「馬達電流」和「馬達溫度」兩項數據。
輸出: 只預測「馬達的剩餘使用壽命」。
這個看似過度簡化的模型之所以成功,是因為它精準地解決了核心業務問題:避免派遣維修人員冒著高風險、花費高昂成本到海上進行不必要的例行檢查。 它體現了設計數位雙胞胎的黃金法則:「盡可能簡單,但不能過於簡化」。
從這個慘痛經驗中,作者歸納出數位雙胞胎設計的五大致命陷阱。本章旨在幫助設計師避開這些陷阱,建立真正有用的數位雙胞胎,專注於解決實際問題而非技術炫技。
數位雙胞胎的五大致命陷阱
1. 建立技術展示品而非實用工具 (Building a Tech Demo, Not a Utility)

問題核心: 過度關注視覺效果和技術複雜度,忽略實際業務價值和用戶需求,導致數位雙胞胎變成昂貴的「數位古董」(digital artifact)。
正確做法: 從業務需求 (business requirements) 出發,專注於可操作的洞察 (actionable insights),簡化介面,突出關鍵資訊。
2. 忽略數據品質和可靠性 (Ignoring Data Quality and Reliability)

問題核心: 假設感測器數據永遠準確和即時,缺乏錯誤處理、數據驗證 (data validation) 和清理機制。
正確做法: 建立數據品質監控 (data quality monitoring),設計多重驗證機制 (redundancy checks),實施異常檢測 (anomaly detection),並制定數據故障時的備援策略。
3. 過度複雜化系統架構 (Overly Complicating the System Architecture)
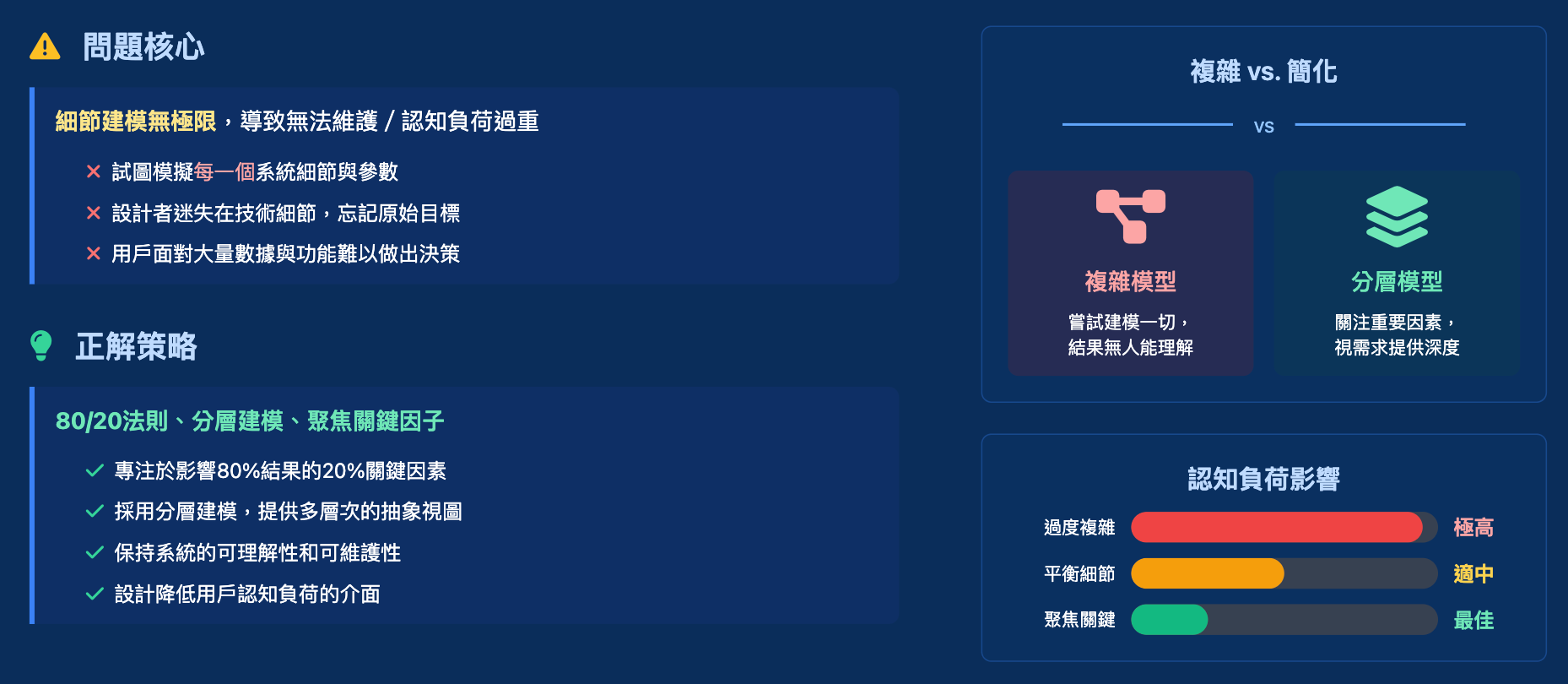
問題核心: 試圖建模每個細節,導致系統無法維護、學習曲線陡峭,並增加用戶的認知負荷 (cognitive load)。
正確做法: 採用 80/20 原則,專注於影響 80% 結果的 20% 因素,採用分層建模 (hierarchical modeling),並保持系統的可理解性和可維護性。
4. 缺乏用戶導向的設計 (Lacking User-Centered Design)

問題核心: 只考慮技術可能性,不考慮實際使用情境、工作流程 (workflow) 和不同角色的需求差異。
正確做法: 進行深度角色分析 (persona analysis),設計任務導向的介面,並建立以用戶工作流程為中心的設計。
5. 忽略漸進式實施策略 (Ignoring an Incremental Implementation Strategy)

問題核心: 試圖一次性建立完整系統(大爆炸式部署, big bang deployment),缺乏原型驗證 (prototype validation) 和早期成功的里程碑。
正確做法: 採用 MVP (Minimum Viable Product) 方法,分階段功能上線和驗證,並持續整合用戶回饋。
核心原則:如何打造一個有價值的數位雙胞胎
數位雙胞胎是理解和建模的基礎練習。就這點而言,它有點像建立人物誌 (persona) 的練習:我的人物誌關心什麼?不關心什麼?

你需要用同樣的方式來思考數位雙胞胎,但這次是針對 AI 系統。它應包含所有能驅動系統操作控制 (operational control) 的面向,並有助於了解該轉動哪些「旋鈕 (knobs)」和按下哪些「按鈕 (buttons)」。
注意 (NOTE): 建立數位雙胞胎的真正價值,在於釐清模型中哪些是必要的、哪些不是,並確定你的模型將實現哪些使用情境 (use cases)。這是一個需要團隊共同參與的過程,就像盲人摸象,集合多方視角才能看清全貌。
實作指南:從零到一建立數位雙胞胎
那麼,我們該如何建立一個數位雙胞胎模型呢?核心流程相當直接:
理解資訊來源: AI 模型的感測器從真實世界收集了哪些資訊?
視覺化呈現: 繪製一張圖,視覺化地呈現物理世界的相關面向。
標註數據: 用傳入的數據標註這張圖。
定義價值: 找出模型可以預測的使用情境和最有價值的測量指標。
盤點缺口: 記下任何遺漏的數據,並與團隊討論如何獲取。
打破孤島: 思考需要打破哪些資訊孤島 (siloes) 來獲取額外數據。
審視倫理: 小心「令人毛骨悚然的 (creepy)」數據結論,例如影響保險費率或貸款資格。
持續疊代: 保持謙遜,保持好奇。疊代、疊代、再疊代!
範例:智慧手錶運動追蹤器的演進
讓我們以智慧手錶運動追蹤器為例,看一個好的數位雙胞胎如何透過疊代逐步演進。
疊代 1:僅使用智慧手錶
輸入: 脈搏、時間。
計算: 靜止與運動心率差異、與同齡人運動後心率恢復速度比較。
輸出: 基本健康水平。
疊代 2:智慧手錶 + 智慧型手機
新增輸入: GPS 座標、海拔、用戶體重/年齡/性別(自行回報, self-reported)。
新增計算: 燃燒的卡路里 (calories burned)、行走異常偵測。
新增輸出: 更精準的健康水平、預期壽命預測。
疊代 3:整合更多數據孤島
新增輸入: 睡眠數據、消費習慣、通勤時間、社交狀況、DNA 數據等。
新增輸出: 極度個人化的健康、壽命、風險預測。
這個例子顯示,透過逐步整合數據,數位雙胞胎的能力可以越來越強大。但同時,倫理問題也隨之浮現。你是否應該收集和建模這些數據?這取決於你的使用情境,以及用戶願意分享多少隱私來換取你的洞察。
注意 (NOTE): 我們是否應該收集特定數據,也取決於你建模的法律和倫理考量。記住,並非所有數據都會被收集它的實體使用——或用於其最初的預期目的!
設計練習範例:人生時鐘數位雙胞胎
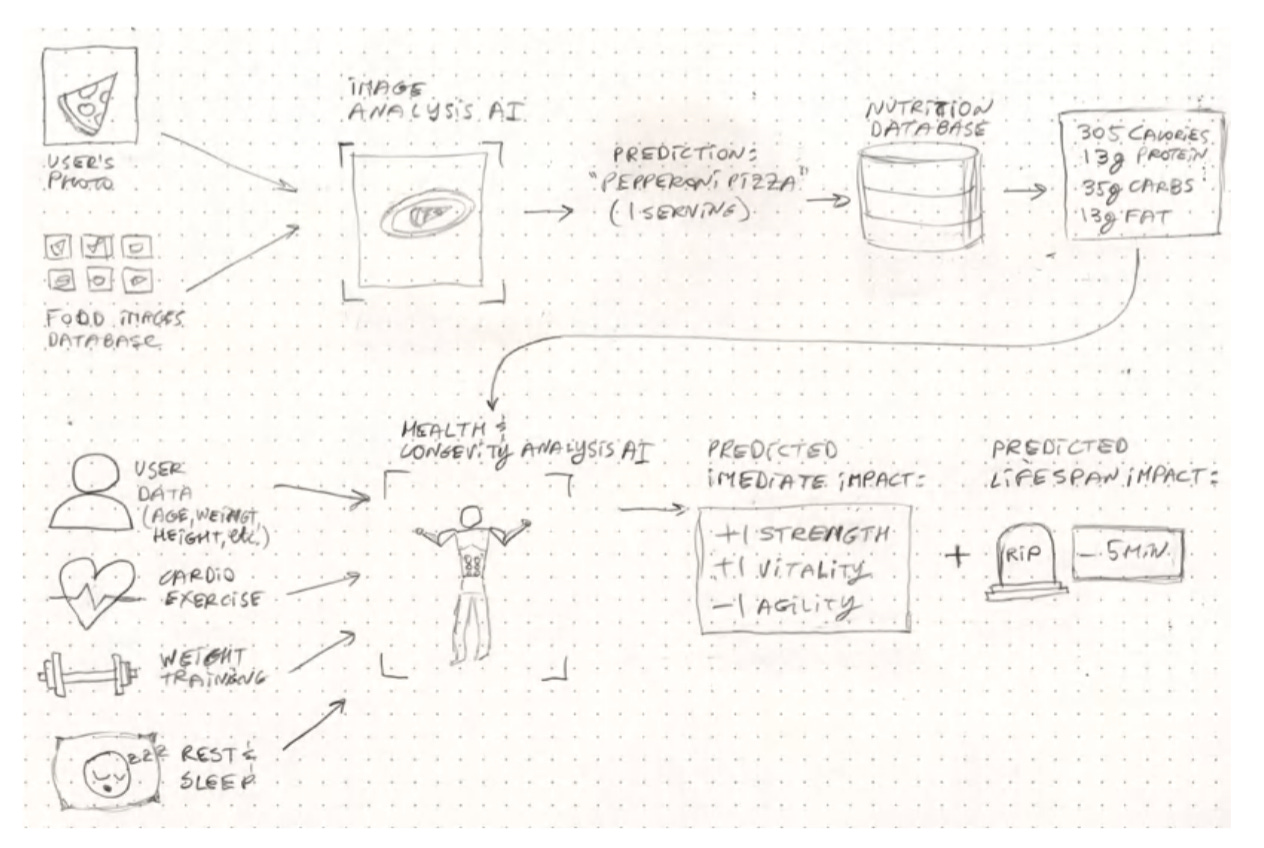
還記得我們在第三章「為 AI 專案進行故事板設計」中提到的「人生時鐘」故事板嗎?這就是我們為該故事板中描述的系統所建立的數位雙胞胎模型(見下圖 )。
在圖表的第一列,我們提供給 AI 一個帶有標籤的食物圖片資料庫,用以訓練我們的模型。當用戶提供一張食物照片時,我們會將其傳入一個圖像分析 AI 模組,該模組會回傳對食物內容和份量的預測(例如:「義式臘腸披薩,一份」)。接著,透過查詢營養資料庫,可以得到基本的卡路里和宏量營養素(蛋白質、碳水化合物、脂肪)數據。
在第二列,這些營養數據會與用戶的個人數據(心肺功能、體重、運動和休息狀況)結合,並輸入到一個健康與壽命分析 AI 模型中。這個模型會回傳預測的即時影響,採用類似龍與地下城(D&D)的風格(例如:因蛋白質而「力量+1」,因高脂肪和高加工碳水化合物而「敏捷-1」),以及對此人壽命的總體預測影響(例如:由於這片臘腸披薩對於久坐的生活方式來說不是最健康的選擇,因此「壽命-5分鐘」)。
如果你正確地完成了數位雙胞胎的練習,你應該會得到一個類似的圖表,但當然,它會對應到你自己可能略有不同的使用情境。
學習要點
從問題出發,不從技術出發。
建立可靠的數據基礎設施。
採用簡化優先的設計思維。
深度理解用戶工作情境。
執行風險可控的漸進式部署。
在關鍵基礎設施中,可靠性比功能豐富度更重要。
實作檢查清單
專案啟動前:
[ ] 明確定義要解決的業務問題。
[ ] 評估數據來源的可靠性。
[ ] 制定 MVP 和分階段部署計劃。
[ ] 進行深度用戶研究和工作流程分析。
專案進行中:
[ ] 定期驗證數據品質和系統可靠性。
[ ] 持續簡化不必要的功能。
[ ] 收集用戶使用回饋。
專案上線後:
[ ] 監控實際使用模式和 ROI。
[ ] 持續最佳化和功能調整。
[ ] 建立長期維護和更新計劃。
讀後案例練習
馬上進入討論,就可以獲取本章節完整投影片內容,並且解答本案例。
名為「GreenGrow」的大型農業科技公司,計畫開發一套「AI 農業大腦」數位雙胞胎系統,用於管理其廣達一萬英畝的商業農場。
背景案例
他們的宏大計劃包括:
部署數千個土壤感測器、氣象站,並搭配無人機每日空拍,以監控作物健康。
建立一個高擬真的 3D 農場模型,能即時視覺化每一塊田地的生長狀況。
AI 模型將分析所有數據,自動化灌溉、施肥、和病蟲害預警。
目標: 節省 50% 的水資源與肥料成本,並提升 30% 的作物產量。

copyright © PrivacyUX consulting ltd. All right reserved.
關於本刊作者
Gainshin Hsiao 是 Agentic UX(代理式使用者體驗)的先驅,在人工智能與使用者體驗設計領域擁有超過 15 年的開創性實踐。他率先提出將用戶隱私保護視為 AI 產品設計的核心理念,於 2022 年創立 Privacyux Consulting Ltd. 並擔任首席顧問,積極推動隱私導向的醫療 AI 產品革新。此前,他亦擔任社交 AI 首席策略官(2022-2024),專注於設計注重隱私的情感識別系統及用戶數據自主權管理機制。
Agentic UX 理論建構與實踐
AI 隱私保護設計準則
負責任 AI 體驗設計
在 Cyphant Group 設計研究院負責人任內(2021-2023),他探索了 AI 系統隱私保護準則,為行業標準做出貢獻。更早於 2015 至 2018 年,帶領阿里巴巴集團數位營銷平台體驗設計團隊(杭州、北京、上海、廣州)、淘寶用戶研究中心並創立設計大學,從零開始負責大學的運營與發展,不僅規劃了全面的課程體系,更確立了創新設計教育理念,旨在為阿里巴巴集團培育具備前瞻視野與實戰能力的設計人才。其課程體系涵蓋使用者中心設計、使用者體驗研究、數據驅動設計、生成設計等多個面向應用。
活躍於國際設計社群,在全球分享 Agentic UX 和 AI 隱私保護的創新理念。他的工作為建立更負責任的 AI 生態系統提供了重要的理論基礎和實踐指導。
學術背景
Mcgill - Infomation study/HCI -Agentic UX, Canada
Aalto Executive MBA-策略品牌與服務設計, Singapore
台灣科技大學:資訊設計碩士- HCI, Taiwan
中原大學:商業設計學士- Media and marketing design, Taiwan