
[Agentic UX 實作-Claude 篇] 別只追五級往上爬:先問「我審得動嗎」,再用 UX Auditor 把每一級該有的判斷對齊
Don't Just Climb the Five Levels—First Ask If You Can Audit It, Then Ground Each Level With UX Auditor

序言:有人花了 400 小時泡在 Claude 裡,拍了一支 20 分鐘的影片,把 Claude 的使用者切成五級—啟動者、入門者、中階、進階、架構師。
影片裡 Anthropic 自家 Claude Code 的負責人 Boris Churnney 同時跑五個 Claude session,「每一個都在自己隔離的 worktree 裡,他把它們全部開出去然後走開,回來時手上是好幾份等他 review 的 pull request」。
聽起來像是終極生產力。但把這個畫面挪進設計團隊的早會就尷尬了—你的設計師同時跑五個 Claude,產出五個概念原型變體,週三的 design critique 上 PM 指著螢幕問「哪個是你做的」,你答不出來,因為全部都是 Agent 產的。
影片預設的方向是「越高越好」,但 UX 工作者面前的問題不是「我要爬多高」,是「我爬到的這級,我審得動嗎?」這篇的苦手問題:Agent workflow 怎麼逐步展開,而不只是逐步加速?
作者補充
我看完那支影片的第一個反應不是「哇」,是「等等」—影片裡每一級的 cheat code 都是「往上爬」,但作者在 L5 那段自己鬆口了一句:「level 5 卡關不是技術問題,是信任問題。」這跟我在〈當 Agent 開始幫你做事〉裡反覆撞的點是同一件事。技術階梯走得快,治理階梯走得慢。影片把這條治理線壓得很小聲,但對 UX 工作者來說,治理才是主線。
上個月跟幾位創業實作向的 UX 社群朋友對談,其中一位是他們團隊裡少數的 AI Builder,其餘多半是 UX、研究、視覺。他說早會最常卡住的,不是「要不要上 AI」,而是沒有共用的工具成熟度刻度:有人覺得開了 Project 就算「上軌道」,有人跑過一次 Co-work 就自認 L3,主管問「我們 AI 化到哪了」時各人報各的用量或各報各的「我有用」—常常是雞同鴨講。他已在內部草擬一份對照表,就為了讓討論先對齊語言,再談要不要往 L4 爬。
同一輪對談裡還聽到另一種錯判:有人早早拉高到「用 Agent 吐 HTML 頁面」,卻不願細讀團隊的 markdown PRD、UX 研究摘要,Figma 圖層也不整理,只靠 screenshot to UI 拼畫面;另一頭則在 POC 還沒過前就花大量時間拋光設計系統。
看起來很 L3,其實跳過了 Summarize 與 Merge Turns—輸入端沒讀懂,輸出端再炫也審不動。
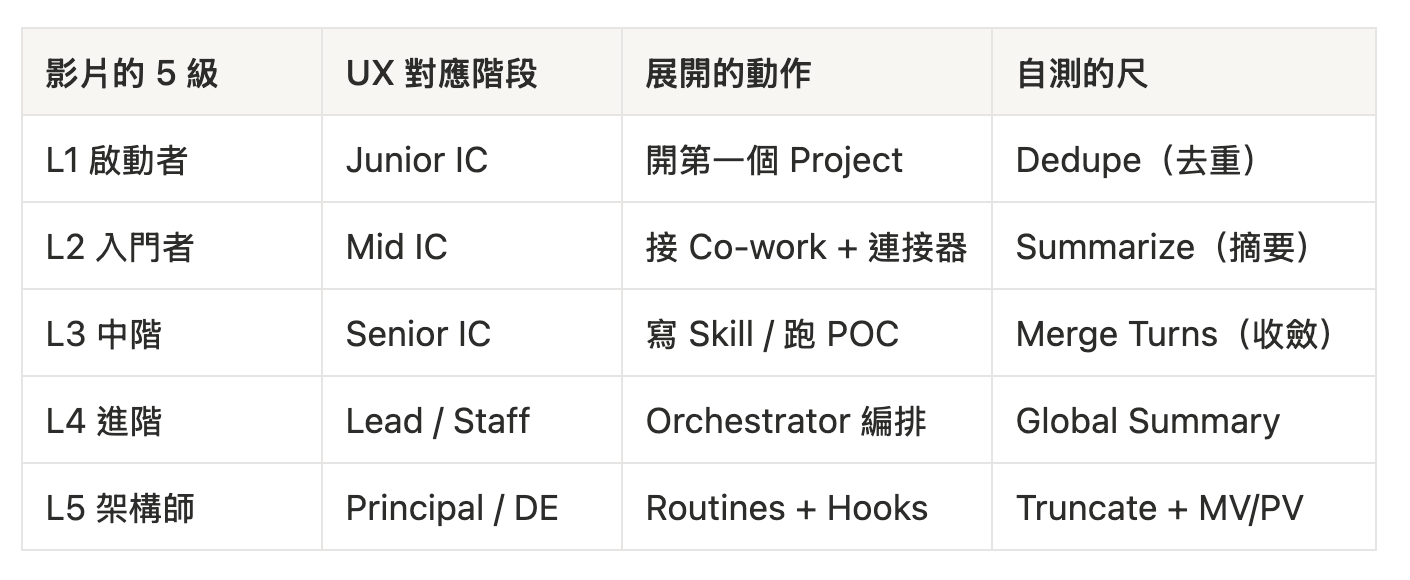
我把影片裡的五級放回 UX 職涯 × Claude 級對照+ 28 種 UX 文件 × Claude 使用判斷)對照重看,發現結構其實是這樣:每一級的「展開」要配一個對應的「自測」。
不然你就只是在更高速地生產垃圾,然後審到崩潰。這篇要做的事,就是把那位朋友草擬的刻度桌,收斂成設計團隊讀得懂的版本。
系列導讀:這是「Agentic UX 實作系列」的番外—前三篇談個人、團隊、組織三個尺度的判斷護城河(執行者 / 管理者 / 治理者)。這篇是橫切面:站在你目前的職涯位置上,怎麼把 Claude 的 Agent workflow 逐步展開 並且 每一步都有自測 地往前推。
對照 28 種 UX 文件產出:每一種文件都有 Tier(A/B/C) 與 最低 Claude 級 + 使用判斷。
Tier C(14%)—線框、視覺、原型、元件—最低 L3–L4 才碰;若 L2 的 PRD/訪談洞察還沒進 markdown,跳到 HTML 就是「假 L3」。

AI/UX 要補的是判斷力與 90° 反問
影片的 5 級是一條乾淨的單向階梯:每一級都有清楚的 cheat code、每一級都讓你「節省更多時間」。但你把這條階梯放進 UX 職涯裡,會碰到一個 Jenny Wen 自己沒講透的限制—不是所有人都該爬到 L5。
這也是為什麼「成熟度刻度」不能只停在影片裡。創業團隊裡常見的裂縫是:少數 AI Builder 已經在編排,多數 UX 還在試 Project;早會上沒有共用語言,就會變成各說各話的 token 數、各說各話的「我有用」。先對齊「你現在在哪一級、該停在哪一級」,比催大家再往上爬一級,更能止雞同鴨講。
影片裡作者明白寫過:「If your day lives in Microsoft Office, this integration changes everything for you.」那是給知識工作者的通用語氣。
但對 UX 從業者來說,Excel / PowerPoint / Word 三件套的 add-in 對 UI Designer 的價值,遠低於對 PM 的價值。
同樣一句「全部三層 share context across these apps」,UI Designer 聽到要去學 PowerPoint add-in 才不會被淘汰,這個翻譯本身就是錯的。
在〈Agentic UX 實作系列-1〉裡,Kai 在 design critique 上答不出「哪個是你做的」—因為他的判斷依據沒寫下來。影片裡 Boris 同時跑五個 session,看起來是 L4 標準動作,但 Boris 是 Claude Code 的負責人,他的 worktree 隔離、CLAUDE.md 寫作、verification loop 全都是他自己定義的—他不是「往 L4 爬」,他是 L4 這個概念的作者之一。
影片的 5 級在 Boris 身上是描述(descriptive),到了你的 junior 設計師身上會變成處方(prescriptive)。
處方化的階梯比描述性的階梯危險十倍—因為它預設「爬上去就是成長」,但 UX 工作者的成長從來不是線性的。
在〈Agentic UX 實作系列-2〉裡,研究員 Maya 用 Cowork 一個下午產出三個帶假設的原型。
她在影片的標準裡是 L3,但她其實是 L3.5—她有 Co-work、有 Skill 庫,但她也有研究員角色不該越過的 Frame 邊界。她超過 L3 不是進步,是越界。影片的階梯只看工具深度,不看角色邊界。
所以我們需要一條 90 度的反問:
影片的軸 UX 必須加的軸 工具自動化深度(L1→L5) 你的角色該停在哪個階段?
一天節省多少時間 一天產生的東西你審得動嗎?
道德皺摺帶(moral crumple zone)這個詞我在〈Agentic UX 實作系列-3〉裡引用過—當每個人都對 Agent 產出負責時,沒有人真正負責。影片把「五個 session 並行」當成 L4 的 cool factor,但對團隊管理者來說,那是責任稀釋的最佳結構。
處方:先回答「你該停在哪一級」,再決定怎麼往那一級爬。
UI Visual / Junior IC:L2-L3 是合理位置。爬到 L4 不會給你加薪,會給你更多自己審不動的產出。
Senior IC / Interaction Designer:L3-L4 是合理位置。L3 是「Skill 寫得好」,L4 是「subagent 跑得起來」。中間那條線就是你下一年的成長軌跡。
Design Lead / Manager:L4 是合理位置。L4 你才當得了 Frame 與 Arbiter(〈系列-2〉)。
Principal / Design Engineer:L5 是本職。harness、hooks、SDK 是組織的基礎建設,不是個人的炫技。
對照圖共用的產品脈絡:UX Auditor、三層審查,與 IC/Manager/Judge
下面每一級(L1→L5)的正反例對照圖,都發生在同一個產品脈絡裡—我這兩年在做的 UX Auditor。先交代它,讀者碰到「audit report」「L3 discussion topic」「Maya 越界」這些詞時,才不會被彈出上下文。
UX Auditor 是一套 AI 輔助的 UX 稽核教學工具,過去給客戶內部團隊用:上傳介面截圖或功能描述,系統會產出結構化審查報告。核心是一個 三層審查模型。
L1 用 Brignull 那套分類在介面裡找 dark pattern(confirm-shaming、roach motel 等)。L2 用 AIPET(Agency、Interaction、Privacy、Experience、Trust)評 agentic UX。
L3 再把介面放回較大的治理敘事裡(例如 NIST AI RMF 這類框架),標出哪些議題值得繼續談。
L1、L2 的產出叫 finding—有位置、有影響、有修正方向;語氣可以直接說「這是 dark pattern」。
L3 的產出叫 discussion topic,帶
confidence: suggestive之類的標記;語氣是「值得討論」「可考慮探索」—不是判決、不是清單、也不是合規檢核。L3 不能變成 finding,在產品裡是硬規則。兩者一混,教學定位就整個塌掉:工具會從「幫設計師看見治理議題」滑成「給介面打分的 QA」。
讀對照時可以代入三種角色。
IC(Individual Contributor) 是主使用者—設計師、UX researcher、學員:上傳介面、看報告、改設計;也是 L1 反例裡那個花三天畫 wireframe、卻沒先讀 NPS 留言的人。
Manager 看的是跨多次稽核的 AIPET 趨勢、團隊哪個維度反覆踩線;對應 L4 反例裡那個該寫 frame.md、卻去趕 80 頁 vision deck 的角色。
Judge(設計評審者)是任務角色,不是預設帳號等級:學員可選擇邀請老師對 AI 報告補教學評語,全流程 opt-in,MVP 以 Email 交付為主;老師回的不是分數、不是仲裁,是教學補充。四格圖裡 Judge 不常直接入鏡,但它的存在撐住整份免責邏輯—工具不替老師打分、也不替平台簽發合規—L3 才能一直維持「討論而非判決」的語氣。
下面各級正反例裡的「反例」多半不是「畫面醜」;是 該寫的文字判斷沒寫。
逐步展開:每一級的動作 × harness 自測尺(Tier A/C 正反例)
選好階段之後,問題變成怎麼從現在站的位置走到下一級。影片給的是「下一級 cheat code」,但 cheat code 只告訴你「按哪個鈕」,不告訴你「按完之後怎麼確認自己沒亂」。
社群裡還有一種常見的「假 L3」:過早把 HTML 視覺化 artifact 當成成熟度證明。設計師把 Figma 截圖餵給 Claude,要它「照這個長一個頁面」,卻不願逐段讀 markdown PRD、UX 文件裡的訪談洞察,也不收研究員回饋進可被 agent 引用的結構;Figma 本體的圖層與命名懶得整理,工作流變成 screenshot to UI 的拼湊。
另一頭則在假設還沒通過 POC 前,就花一整週調設計系統 token,只為了讓 HTML 看起來像正式產品。影片的階梯會把這種產出記成進步,團隊真正缺的卻是輸入有沒有被讀懂。若你答不出「這屏對應 PRD 哪一條、呼應或反駁了哪則研究發現」,你只是在用 AI 做視覺拼貼,不是在升級工作流。
這就是 C4 那套 harness 五層的真正用處。Harness 原本是 LLM agent 工程的概念—管 context window、做壓縮、避免 token 爆掉。但我在 C4 裡做的映射是:把這套壓縮策略當作設計團隊的 context 治理紀律。
把它再壓一次,這套五層也可以當「Agent workflow 逐步展開時的自測尺」—每升一級,配一個壓縮動作。
L1 啟動者 → L2 入門者 · 自測:Dedupe

展開動作:開第一個 Project。把 persona、設計系統 token、品牌資料丟進去,寫一段 50 字的 system prompt。
自測尺(Dedupe):你過去三週貼給 Claude 的 context,有多少是重複的?同一段 brand guideline 你已經貼了七次嗎?「同一份 Figma 截圖各自寫了類似 comment」(C4 L1 原文)這種事在 L1 看不見,但已經在發生—只是發生在「你和 Claude 的對話」裡,而不是「你和同事的會議」裡。
走到 L2 的訊號不是「我開了 Project」,是「我發現我沒再貼那段 brand guideline 了」。如果你開了 Project 但還是每次都重貼,你的 Project 設置是壞的—回頭修,不要往 L3 跑。

{合作廣告}

🧑🎓 UX 訂閱制學習計劃:把 human-in-the-loop 變成你的日常。這也是我會特別推薦 #UX訂閱制學習計劃 的原因:它不是一次性的 bootcamp,而是把借位、補位、入位拆開來,串成 3 月到 12 月的一條學習軸線。透過每月 Podcast 和專欄,先向不同領域的 UX / 產品 / AI / 服務設計講師「借位」
透過直播與 Circle 社群討論,在你的真實案子與問題上進行「補位」
